ContinueによるRPGでのAIペア プログラミング
前回の記事では、GitHub Copilot拡張機能について簡単な紹介を行いました。これらの拡張機能は、RPG開発を支援するために、AIコーディング アシスタントを簡単に稼働する方法を提供します。クラウド ベースであることから、システム リソースの点では軽量ですが、少し費用(ユーザー当たり、月額)が掛かります。
今回の記事では、「Continue」というVS Code向けの新しい拡張機能について私が学んだことを紹介しようと思います。ContinueはPC上でローカルに稼働し、100%無償で、本稿執筆時点で最先端のオープンソース AIコード アシスタントです。
昨年10月のTechXchangeの際、IBMのソフトウェア開発者、Adam Shedivy氏にお目に掛かる機会がありました。Adam氏は時間を惜しむことなく、Continue拡張機能によって、私にとって初めての自己ホスト型AIコード アシスタントの手ほどきをしてくれました。
まずは、ご自分のコンピューターでローカルに大規模言語モデル(LLM)を稼働できるようにするツールをダウンロードする必要があります。ツールは何種類かありますが、良くも悪くも、私はOllamaを選びました。Ollamaは、かなり人気のようで、Windows、macOS、およびLinuxで稼働することができ、そしてオープンソースです。ともあれ、Ollamaは、こちら( https://ollama.com/download/windows)でダウンロードすることができます。
次に、VS Codeで、拡張機能マーケットプレースへ移動し、Continue拡張機能を検索してインストールします。次いで、使用する大規模言語モデル(LLM)を1つインストールします。Qwen 2.5 Coderモデル シリーズ内のLLMの違いについては、こちら( https://ollama.com/library/qwen2.5-coder )で確認することができます。私は現在、1.5bおよび7bバージョンの両方を使用しています。7bバージョンをインストールするために、VS Code内のPowershellターミナルで「ollama run qwen2.5-coder:7b」というコマンドを実行します。

これらのLLMはサイズが非常に大きくなることがあるため、携帯電話のホットスポット経由での接続時や、ラガーディア空港でフライトを待っている間に(後ろめたいので)、これをダウンロードすることはお勧めできません。たとえ快適な接続環境が得られたとしても、自宅またはオフィスに戻ってからダウンロードすることをお勧めします。完了したら、listコマンドを使用して、このLLMがロードされていることを再確認することができます。
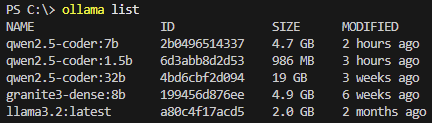
次に、Continue拡張機能にモデルを追加します。
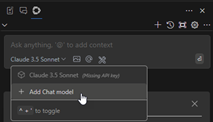
「Add Chat model(チャット モデルを追加)」画面で、プロバイダーを「Ollama」に変更し、モデルを「Autodetect(自動検出)」に変更してから、「Connect(接続)」をクリックします。すると、ドロップダウン リストに、「Autodetect - qwen2.5-coder:7b」というオプションが表示されます。以下の画面キャプチャーでは、他のモデルもいくつか試していたことが見て取れます。それらも同じように自動検出されました。
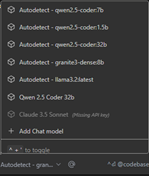
これで、モデルに何でも尋ねることができるようになりました。Continue拡張機能は、「@」とトピックを指定することで質問を開始してコンテキストを追加する機能をサポートしています。これにより、モデルから返される回答の有用性を大幅に向上させることができます。たとえば、リクエストに対するレスポンスが、コンテキストとしてDB2 SQLをベースにするようにしたい場合、リクエストの先頭を「@Db2i」にすることもできます。詳しく掘り下げてみたいことはたくさんありますが、別の機会に取っておくこととします。
オートコンプリート向けのLLMは、チャットで使用されるものとは異なることがあり、おそらくは異なるはずです。Adam氏の知見によれば、そして実験で確認されたところでは、より小規模なLLMの方が、オートコンプリート提案のプロンプトがより迅速であるようです。しかし、より大規模なLLMの方が、チャットの際に、よりしっかりしたレスポンスを提供することができるようです。そして、これまで見てきた限りでは、Qwen2.5-coderの1.5bバージョンは、他のバージョンと比べても遜色ないコード補完提案をプロンプトしているようです。また、処理速度の違いは非常に顕著なものがあります。
GitHub Copilotと同じような「tab to complete(Tab補完)」機能を利用するには、Continueのconfig.jsonファイルを編集する必要があります。VS Codeで、F1を押してから、「config.json」と入力し、Enterを押します。改行して、以下のJSONのスニペットをペーストします。
{
"tabAutocompleteModel": {
"title": "Qwen2.5-Coder 1.5B",
"provider": "ollama",
"model": "qwen2.5-coder:1.5b"
}
}変更内容を保存したら、ライブラリーでソース メンバーを開きます。コード補完提案は、かなり正確であるだけでなく、非常に迅速でした。
PCでローカルにLLMを稼働することについて検討する場合は、パフォーマンスについても考慮することが不可欠です。ローカルでのOllamaおよびLLMの稼働について調べ始めたときには、まずは、Qwenオファリングの中で「最も強力」と思えるものを目指して、qwen2.5-coder:32bをインストールしました。私が使用していたノートPCは、第12世代Intel(R) Core(TM) i7-1255U 1.70 GHzおよび64GBのRAM搭載のDell Precision 3570で、私には、32b LLMからのレスポンスを待つのに十分な忍耐力がありませんでした。その後、7b LLMをロードして、レスポンスを受け取れるようになりましたが、処理速度を向上できるのかどうか知りたくなりました。
パフォーマンスについての話をするときは、常に「物差し」が必要になります。基準値を設定し、パフォーマンスの向上をテストするために、VS Code内のPowerShellターミナルに戻り、詳細モードでモデルを稼働するようにOllamaに指示しました。次いで、テストとして、「How much rain is the equivalent of 6 inches of snow?(6インチの降雪は、どれくらいの雨量に相当するか)」という質問をOllamaに尋ねました。

すると、雪の密度、水の重量などを検討している、興味深いレスポンスを受け取りました。-verboseスイッチを指定してモデルを稼働したため、パフォーマンスについての統計情報もいくつか取得できました。私が注目したのは、total duration(所要期間)とeval rate(評価速度)の2つです。
| total duration(所要期間) | 40.2912856秒 |
| eval rate(評価速度) | 4.63トークン/秒 |
これで、測定の基準値を設定できました。ところで、これらのQwenファミリーのLLMは、新規インストールでは、利用可能なコアの半分だけを使用し、システムRAMは半分以下しか使用していませんでした。この点については、長いディスカッションが行われています( https://github.com/ollama/ollama/issues/2496)。しかし、私はnum_threadパラメーターを私のコア数(10)に合わせてみようと思いました。

次いで、まったく同じ問題を尋ねたところ、レスポンスは多少異なりましたが、雨の重量や雪の密度などについての検討は相変わらずでした。メトリクスでは、以下のようにかなりの改善が示されました。
| total duration(所要期間) | 27.6182394秒 |
| eval rate(評価速度) | 6.82トークン/秒 |
これで良い出発点ができました。ここまでで、Continue拡張機能をロードして使用する方法、様々なLLMを評価する方法、およびパフォーマンスを調整する方法について、お分かりいただけたかと思います。ご自分のシステムで調べて、様々なLLMを試し、どの組み合わせが最もうまく機能するか確かめてみることをお勧めします。
CoPilotなどのような有償のコード アシスタントと比べてみると、Continueは完全に無償ですが、セットアップに多少手間が掛かり、また、RAMをアップグレードしたくなるかもしれません。しかし、CopilotのようにAIリクエストをクラウドで処理するのが心配な方にとっては、ContinueはすべてのAIリクエストをローカルで処理できるという点は、大きな利点と言えるでしょう。
それでは、また、次回の記事で。楽しいコーディングを。










