物事は変われば変わるほど、実は元に戻って来る
ほとんどの読者の皆さんと同じように、私も、アルフォンス・カール(Jean-Baptise Alphonse Karr)の自伝的な恋愛小説を読んだことはありませんし、2世紀近く前にカールが編集者だった頃の、風刺に富んだ『 ル・フィガロ 』紙の記事を読み返したこともありません(同紙は、今日では上層中流階級向けで、フランスの信頼が置ける新聞の1つとされています)。
しかし、ほとんどの読者の皆さんと同じように、私も、カールが著した格言に、非常に馴染み深いものが1つあります。すなわち、「Plus ça change, plus c'est la même chose.」です。米国では、「The more things change, the more things stay the same.(物事は変われば変わるほど、実は元に戻って来る)」という訳で知られています。私としては、高校と大学で学んだフランス語を頼りに自分なりに訳した、より逐語的な訳の方がしっくりきます。「The more it changes, the more it's the same thing.(変化はすればするほど、同じもの)」 こちらの方が苛立っている含みが込められていて、カールの言わんとしているところに近いような気がします(直感で言っているだけですが)。
これは、ただ何となくそんな気がしたというだけの話です。話の枕として聞き流してもらえればと思います。
フランス語の「 plus 」は、「more(より多く)」という意味ですが、英語の「plus(プラス)」は、数学で加算を意味することもあれば、見た目がまったく普通の人向けの服のサイズを意味したりすることもあります。服のサイズというのは無茶苦茶なこともあり、女性をがっかりさせるためにあるのかとさえ思われ、何かを保証するわけでも、存在する意味があるわけでもないように思われます。男性の服のサイズでは「ビッグ(恰幅が良い)」や「トール(背が高い)」が用いられますが、他の男性と比べて背が高かったり、恰幅が良かったりする(あるいは同時にその両方)ということはよくあることですが、これらの用語には「F」で始まる言葉の意味合いはありません。妻と3人の娘がいる私としては、こうした無意味な言葉は勘弁してほしいという思いがあります。また、女性の服は薄手の生地でできていて、たいていはポケットがないということにも頷けないものがあります(後者については少し分かります。女性はある程度ぴったりフィットするものを求めますが、ポケットは服のラインの邪魔になります)。ちなみに、私はと言えば、やせ型で背が高いのですが、恰幅が良くて背が高いのと同じように鬱陶しい思いをすることがあります。背が高いなら、恰幅も良いに違いないという前提のせいで、人生の大半で、ぴったりフィットする服を着られたことはありませんでした。
Power Systemsの世界では、「plus(プラス)」には、非常に重要で有用な意味合いがあります。後ろに「+」(プラス記号)が付いているPowerプロセッサー(Power4+、Power5+、Power6+、Power7+、および不運なPower8+、そしてIBMが「プラス記号(+)」から「プライム記号(')」へ記号を変更したときの、あまり見慣れないPower9')は、世代と世代の間の製品サイクルの途中で、それでもなおPower Systems顧客に何らかの価格性能比上のメリットをもたらす、CPU世代間の中間地点であることを意味します。
これまでの例では、Power CPUの「プラス」バージョンは、プロセス シュリンクや、マイクロアーキテクチャーに対する小さな微調整が行われたことを表す名称でした(それらは、Intel社で言うところの、Xeonサーバー チップをアップデートする2サイクルの方式について「ticking(チク)」と「tocking(タク)」と呼んでいたものに相当します。過去20年間にわたってそう呼ばれていましたが、チク(ticking)する方法を忘れ、タク(tocking)に行き詰まったようです。IBMとそのファウンドリー パートナー(販売数量の観点から見て比較的小規模であるPowerチップ向けの市場と同様に)は、同時にチクとタク(ticktocking)に行き詰まりました。これは、1980年代および1990年代にチップ メーカーがしばしばそうなったのと同様です。以下は、2015年のOpenPowerロードマップです。その辺の事情を知るのに参考になると思います。
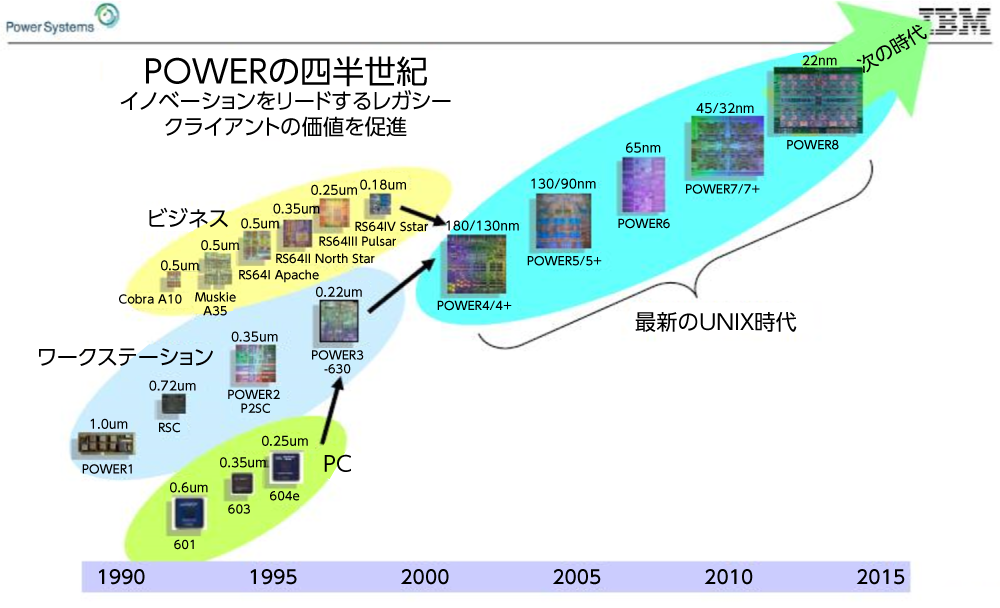
1990年代のPowerPC AS/400や、同じ時期のRS/6000ワークステーションおよびサーバー プロセッサーでは、IBMは、CPU設計とプロセス シュリンクで同時に大きな変更を行うのが通例でした。これは、特に、1年または2年の間隔では、ある程度のリスクを伴いました。2001年の、統合されたAS/400-RS/6000 Power4プロセッサーのリリースでは、IBMは、PowerPC AS 「S-Star」設計(これは間違ってRS64IVチップと呼ばれていました。IBMオースチンの言うところでは、これはIBMロチェスターの責任だそうです)で使用された独自の180ナノメートル製造プロセスで横滑りを行い、命令セットおよび新たなコアの完全な新規実装を行いました(また、1つのダイにそれらの2つを搭載)。Power4+は、130ナノメートルへのシュリンクであり、Power4チップの1.1GHzからPower4+チップの1.3GHzへと、クロック スピードが引き上げられました。Power5は、まったく新しいPower5コアでの130ナノメートルへの横滑りでした。Power5+では90ナノメートルへのシュリンク、そしてソケット当たり2基のチップを収め、パフォーマンスの大幅な向上が実現されました。
2000年代末にPower6およびPower6+でおかしな事態になりました。2009年4月の記事「 Come On Out, Power6+, You Win 」、「 IBM Launches Power6+ Servers-Again 」、および2009年5月の記事「 New Power6+ Iron: The Feeds and Speeds 」で取り上げたように、IBMには、Power6、次いでPower6+でのプロセス シュリンクのプランがありましたが、一部の機能はPower6に引き入れられ、予想されていたパフォーマンス向上やプロセス シュリンクはまったく計画通りには起こりませんでした。IBMはPower5+からPower6への横滑りの90ナノメートル プロセスを行わず、アーキテクチャー変更とプロセス変更を同時に行おうとしたものの、Power6およびPower6+チップの両方で使用した65ナノメートル プロセスに期待したクロック スピードの70%~80%が得られたのみだったようです。昔の話ではありますが、Sun Microsystems社およびHewlett Packard社によるRISC/Unixボックスの売上が減少し、データセンターでIntel Xeonプロセッサーが増加したのと時を同じくしてIBMがパフォーマンスを押し上げようとしていたことを物語っています。上述のロードマップでは、Power6+については触れられていませんが、Power6と呼ばれていたものの多くが実際はPower6+だったということは確信を持って言えます。
Power7ラインアップでは、IBMのチップ アーキテクトは必死になって、45ナノメートルへのシュリンクをフル活用して、アーキテクチャーを変更(コア数4倍、コア当たりの同時マルチスレッドの増加、ダイに組み込まれたDRAMを使用してエッチングされたL3キャッシュの増加)したことで、徹底的にSun社およびHP社を圧倒し、Intel社のX86プロセッサーにおおむね後れを取らずに進むことができるようになりました。Power7+では、32ナノメートル プロセスへのシュリンクと、アーキテクチャーに対する若干の微調整が行われました。Intel社初のCTO(最高技術責任者)職に就任し、2000年代には同社のデータ センター グループの経営に携わり、また、Intel社のチップ進化の チクタク 方式の考案者でもある、Intel社CEOのPat Gelsinger氏なら好意的に見てくれただろうと思います。
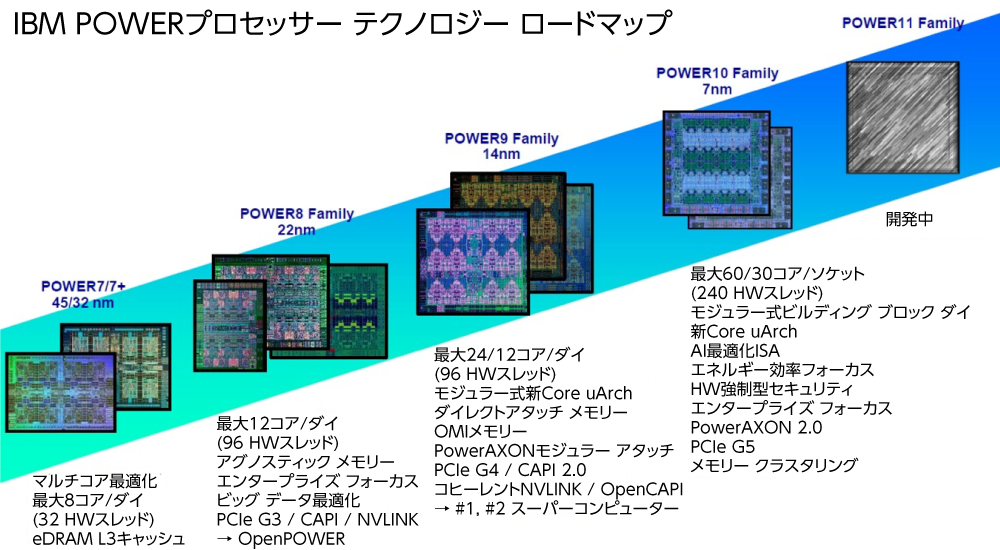
Power8およびPower9では、IBMは、新たな設計とプロセス シュリンクを行い、また、「プラス」方式のアップグレードも計画していましたが、それらについて正式に確約するべく、ロードマップにそれらを実際に載せることはしませんでした。Power8+は、GPUアクセラレーション サポートの強化を行うことが予定され、Power9'は、Power9設計でメモリー スループットを劇的に向上させるためにPower10チップで使用された差動メモリーの初期エディションを導入することが予定されていました。どちらの「プラス」ステップも、設計されたものの、市場投入されることはありませんでした。
Power10チップでは、IBMにはアーキテクチャー変更を行う時間がたっぷりありました。GlobalFoundries社が実用的な10ナノメートルまたは7ナノメートル プロセスをIBMに供給できなかったからでした。そのため、IBMは、7ナノメートル プロセスを入手するためのファウンドリーをSamsung社へ切り替えることを余儀なくされました(Samsung社には、サーバー チップに適した、初めての複雑な高性能トランジスター設計が提供されました)。そして、IBMは、もう一度、コアだけでなくISAの再実装を行い、優れたパフォーマンスを実現しました。
ただし、Power10は2022年7月にローンチされました。もう1年以上前のことになります。2024年は、まだ1年丸ごと残っていますが、新たな機能や、Power10と比べてより多くの費用対効果をもたらし(重要なことです)、したがって世界各地のデータセンターで日々進歩し続けているX86そして今ではArmアーキテクチャーに遅れずについて行くことができるPower11チップが登場するまでには、2025年のいつ頃まで待つ必要があるのかは誰にも分かりません(そして、POWER10ではなく、Power10と表示されるようになったことに対して、もう一度ありがとうと言いたいと思います。もう大文字だからと言って叫ばなくても大丈夫です)。
端的に言えば、プロセッサー世代間の間隔が3年または4年というのは長過ぎます。Power Systemsサーバー ラインアップを混乱させることなく、顧客には顧客が購入したいものを、パートナーにはパートナーが販売したいものを提供する必要があります。新たなソケットまたは新たなシステムを必要とするような、おかしなことは誰も提案しません。
興味深い選択肢はいくつかあると思います。まず、Power10+チップを作るためには、IBMは、データや資源を子細に調べて、コア数がより多いプロセッサーを取り出すことができます。Power10のダイ上には実際には16個のコアがあります。それは見事に設計されたチップであり、 こちらの記事で述べたように、検討しているプロセッサー フィーチャーに応じてどれでも、それらのコアのうちの1個から12個までのどれでもアクティベートされます。多くのケースでは、16個のコアのうち、4個、8個、または10個のコアだけです。分数の計算をしてみれば、かなり低い歩留りです。何を言われようと構いませんが、このことが暗に示しているのは、2022年にはSamsung社の7ナノメートルEUV(極端紫外線)プロセスの歩留りがあまり良かったはずはありませんが、GlobalFoundries社またはIntel社の実在しない7ナノメートルEUVプロセスよりはましだということです。16コアのPower10を販売することができるのであれば、IBMは間違いなく、そうしているでしょう。ところが実際は、IBMがロードマップで言及していたのは15コアについてだけであり、最大で12コアを提供しています。IBMは、1つのソケットにこれらのチップを2個置くか、または、コアのない2つ目のソケットをI/O拡張として使用することができます。実際、これは非常に賢明なやり方です。しかし、来年の夏までには、Samsung社は、仮に具体化するとすれば、Power11およびPower12チップ向けに、4ナノメートル(SF4EおよびSF4X)、3ナノメートル(SF3EおよびSF3X)、2ナノメートル、および1.4ナノメートル プロセスだけでなく、十分に成熟した7ナノメートル7LPPプロセスおよび成熟した5ナノメートル プロセス(SF5E)に対しても改良を計画するでしょう。IBMはPower11にSF3Xを使用し、コアにはるかに多くのものを詰め込むだろうと思います。
しかし、Power10とPower11の間の橋渡し役が必要であり、それがPower10+チップなのです。したがって、IBMは、ごみ箱をかき分けて調べて、12個~16個の間で動作するコアを見つけ出すべきです。そして、4コアだったとしたら、6コアにします。6コアだったとしたら、8コアまたは10コアにします。2、3年前にIntel社が14ナノメートルで足止めされた「Cascade Lake」Xeon SPプロセッサー フェーズの際にそうあるべきだったように、本当に利他的でありたいのなら、追加のコアは無償で提供するのです。コアを追加し、クロック スピードを上げ、そのまま7ナノメートルに留まることができるのなら、そうするのです。真のコストは、何でしょうか。新しいマスクに数億ドルを費やすというのではありません。Samsung社がやることになっている仕事をやるように求めるということです。そして、ムーアの法則が残したどのようなものからでも顧客が恩恵を受けられるようにすることです。
企業に新しいアイアンを購入したいと思わせるようにします。企業が見逃せないようなオファーを提案するようにします(企業が拒絶できないオファーを提案するのではなく)。 利他的になって 、IBM iおよびAIXベースに、ご愛顧に対する感謝の意を伝えるようにします。世界全体では、IBM iおよびAIX顧客はおよそ16万社に上ります。そして、おそらく約60万台のマシンがあり、およそ200万個の論理区画があります。そして、そうした顧客のおそらく1/6~1/7は、いつでもアップグレードを行いたいと思っています。Power11ローンチ前のおそらく20か月前後に予定されていることに向けて資金を用意します。今後その時までにアップグレードする必要があるか、または、LPARでより大型のアイアンへ統合する必要があるマシンは、おそらく14万台ほどあります。
次いで、CXL 3.0プロトコル(主にIntel社によって開発)およびNVLink 4プロトコル(Nvidia社によって開発)のサポートを、Power10デザインの「BlueLink」I/Oポートに追加します。
生成AIブームやNvidia GPUの不足を考慮すると、NVLink 4.0ポートは、現時点で追加するべき一番重要な機能であるかもしれません。GPUの使用率を向上させるのに役立つものがあれば、企業はそれらをより必要としなくなることになります。3万ドル~4万ドルを支払って「Hopper」H100 GPUを購入するとなれば、これは大きな出費です。そして、これらのGPUの使用率は、想定されるほど良好ではありません。それらのGPUは、3TB/秒を超えるくらいの集約メモリー帯域幅で、80GBまたは96GBのHBM3eメモリーを搭載しているだけだからです。本来はDRAMメモリー バッファーを供給するために、 Nvidia社は、「Grace」72コアArmサーバーCPUをHopperと密結合させてきました が、480GB(CPUカード上の合計512GBのうちの)となるだけです。IBM Power10チップは、4TBのメモリーをサポートしています。3.2GHzで稼働するDDR4メモリーで、IBMは、OpenCAPI Memory Interface(OMI)差動メモリー ポートにわたって、410GB/秒のメモリー帯域幅を実現することができます。IBMが、6.4GHzで稼働するDDR5メモリーに移行するとしたら(プロトコルがOMIコントローラー内ではなく、メモリー スティック上にあるので移行できます)、ソケット当たり820GB/秒を実現できるでしょう。IBMが、Power10をGDDR6グラフィックス メモリー( 2020年に何回かのPower10プレゼンテーションで大々的に紹介)を使用するように移行するとしたら、HBM3eよりはるかに安価なメモリーで800GB/秒の帯域幅を実現することもできるでしょう。
Graceチップは、480GBのLPDDR5メモリーから546GB/秒を実現することができるのみです。
Power9チップがNVLink 2をサポートしていたことを覚えておられるでしょう。CPUおよびGPUコンプレックスにわたって一貫性のあるメモリーを提供し、IBMがオークリッジ国立研究所(ORNL)およびローレンス・リバモア国立研究所(LLNL)のスーパーコンピューティングの大型案件を受注することを可能にしました。NVLink 4サポートにより、IBMは、Power10 CPUとNvidia H100 GPUを共有メモリー コンピュート コンプレックス(おそらく4つのGPUと1つのCPU)に密結合させることができ、また、Power10チップ上の他のBlueLinkポートおよび 「メモリー インセプション」メモリー エリア ネットワーク を使用して、これらのユニットを密結合させ、InfiniBandまたはEthernetネットワーキングを一切使用しない、帯域幅がはるかに集約され、より低遅延のGPUクラスターを作成することができます(おそらく、より低コストで、非常に高価なそれらのGPUのより高い使用率を実現)。
IBMは、どのようにしたら、自身の得意な分野でNvidia社に対抗することができ、と同時にAI顧客も支援することによって、Nvidia社(そしておそらくAMD社)を支援することができるかについて考え始めるべき時です。
最後に、Power10+チップは、CXL 3.0メモリー拡張およびメモリー プーリング プロトコルをサポートするはずです。Power10+チップ上のそれらのPCI-Express 5.0ポートはこれが可能であり、また、BlueLinkポートもおそらく可能となるでしょう。これにより、より多くのメモリーをソケットに追加でき(4TBの容量を考えると、それほど重要ではありませんが)、あるいは、より低容量のDIMMを使用して、より多くの容量を追加することができ、費用を大幅に抑えることができる(これは非常に重要です)ようになるでしょう。
ここには、IBMが、これまで築き上げてきたシステム アーキテクチャーの基盤でお金を儲ける機会も、既存のIBM iおよびAIX顧客を幸せにする機会もたくさんあるのです。