Power10チップ アーキテクチャーを深く掘り下げる

先週の記事では、先週の「Hot Chips 32」チップ カンファレンスでのプレゼンテーションに先立ってIBM技術チームから受けていた、ロードマップについてのブリーフィングを元に、IBMの今後のPower10チップに関する概要情報について紹介しました。プレゼンテーション前ではあったものの、月曜日の朝が記事の締め切りということもあり、IBMは、Power10チップについての概要情報を紹介する記事については掲載を許可してくれていました。そしていよいよ今週は、Power10アーキテクチャーの詳細についてさらに詳しく掘り下げることができます。
Hot Chipsでのプレゼンテーションは、IBMの数世代のPowerチップに携わってきた、Power10プロセッサーのチーフ アーキテクトであるWilliam Starke氏と、エネルギー効率に重点を置いてPower10コアをゼロから開発する任務を担ったPower10コア アーキテクトのBrian Thompto氏によって行われました。他にも、Cognitive Systems部門担当バイス プレジデント兼オファリング マネージャーのSteve Sibley氏をはじめ、数多くのPower Systems関係者の話を聞いて、新たなチップに関する知見を深めることができました。素晴らしいプロセッサーおよびさらに興味深いシステム アーキテクチャーを作り上げたことに関して、Power10チーム全体が祝福を受けるに値すると思います。IBMもいろいろと問題を抱えているかもしれませんが、こうした方々が今でも世界最高レベルにあると言い切れます。また、コンピューター オタクを数多く知っていますが、概して、彼らは厳しい環境でエンジニアリングの厄介な業務に取り組む善良な人物です。
今後数週間をかけて、Power10の技術の皮を一枚一枚剥がして行きながら、プロセッサー アーキテクチャーおよび設計、Power10が生み出すシステム設計、Power7、Power8、Power9と比較して予想されるPower10チップの性能などについて見て行くつもりです。そして一連の記事の最後には熱を込めて)、新たなクロスシステム メモリー クラスタリング技術について詳しく見て行くつもりです。この技術は、クラウドのみならず、おそらくあらゆる分散型コンピューティングでのPower10プロセッシングの使用にとって、きわめて重要な技術となるはずです。この最後のところが大事なところであり、これこそが、IBMが実際に取り組んでいたとは知らずに、 この数週間、私が『 The Next Platform 』誌であれこれ思いを巡らしていたことでした(この取組みを推し量る材料はすべて揃っていたにもかかわらず、私はそれらを在りもしない宇宙のエーテルに漂うもののように思っていたのです)。このメモリー クラスタリング技術は、数十年にわたってIBMがスーパーコンピューターだけでなくAS/400ラインでも採用してきたメモリー共有の概念が基になっているため、IBMからすれば進化形ということになりますが、他にこのようなものはないため、業界からすれば革命的と言えるかもしれません。今すぐにでも、この話の続きをしたいところです。
しかし、今週は、Power10チップ本体について見て行くこととしましょう。ちなみに、どうやらIBMはイケてるコード名を付けなかったようなので、私たちは「Cirrus(巻雲)」というニックネームを付けました(ださいニックネームだったかもしれませんが、ないよりはマシということで、 Cirrus としました)。
まずは、ダイのレベルからスタートして、内側へと進んで行くこととしましょう。次の画像をご覧ください。

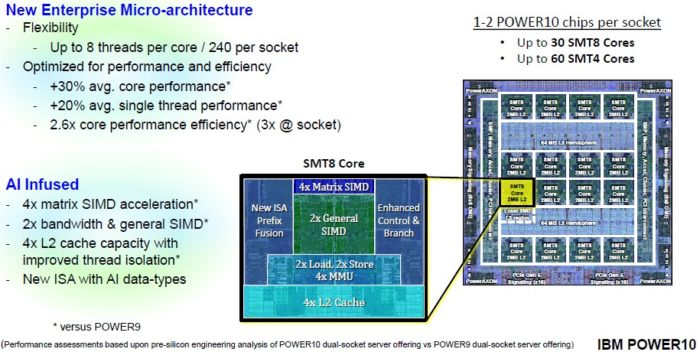
先週の記事で述べたように、Power10の当初のプランとしては、概ねPower9の設計をベースにして24コア プロセッサーをアップデートしてから、それらのチップ2つを単一のソケットに組み込んで、GlobalFoundries社のファブでの14ナノメートルから7ナノメートル極端紫外線(EUV)技術へのプロセス シュリンクによる24コアへと引き上げる、というものだったようです。途中のいずれかの時点、おそらく、GlobalFoundries社が2018年8月に7ナノメートルの開発を中止したときから、 Power10のファウンドリーをSamsungへ移行するとIBMが公式に発表したとき までの間で、IBMはより積極的なプランに移行したと思われます。分かっていることは、IBMがPower10コアをいったん白紙に戻したということであり(Thompto氏に確認しました)、このダイから見て取れることは、602平方ミリメートルのダイの中に180億個のトランジスタを組み込めたおかげで、IBMは限界の壁をもう少し押し広げたということです。
Power10チップは、コア当たり8スレッド(IBM用語でSMT8)のコアをサポートするバージョン、またはコア当たり4スレッド(SMT4モード)の2つのコアをサポートするバージョンのいずれかで提供されます。IBMは単一チップをどちらのモードでも稼働するように設計してきたと強く疑われますが、このモードは、ハードウェア自体に組み込まれているため、IBMによっても、エンド ユーザーによっても再設定することはできません。そのモードをユーザーが変更できないということは、IBMとサードパーティ ソフトウェア サプライヤーは、コア当たりどのような負荷をかけたらよいか分かっているということを意味します。IBMは、以前にPower8およびPower9で行ったように、SMT4またはSMT8コアを調整し、一定の顧客のニーズに応じてそれらを設定するでしょう。SMT8コアは商用ワークロード向けに使用され、SMT4は、HPC、ハイパースケーラー、およびクラウド顧客向けに使用されます。そこでは、ほとんどのケースにおいてマシン当たりで可能な限り多くのVMが求められます(VMをコアに固定している場合)。
上に示したダイの図から見て取れるように、Power10ダイ(IBMがHot Chipsで披露していたバージョン)にはSMT8モードの16個の物理的なコアがありますが、もちろん、SMT4モードでは32個の物理的なコアがあることになります。7ナノメートル プロセスでのチップの生産性を向上させるために、IBMは、1つ以上のSMT8コアとその8MBのL3リージョンが不良となるとみなしました。そのため、Power10を15コアSMT8チップと呼んでいます。しかし、正確に言えば、SMT8モードでは1つ多くのコアがあり、SMT4モードでは2つ多くのコアがあることになります(関連付けられている4MBのL3キャッシュがあります)。
Power8およびPower9の場合と同様に、L3キャッシュはチップ全体で共有されます。一方、コアは、コアと、そのコアが一番隣接しているキャッシュ セグメントとの間で「提携」関係を結びます。無効なコアの分を考慮しても、Power10チップ1つ当たりで最大120MBのL3キャッシュがあります。そのL3キャッシュは、IBM独自の混載DRAM(eDRAM)技術でエッチングされているわけではありません。これは、標準的なSRAMに比べて少し大きいサイズでしたが、ビット セル当たりの消費電力はSRAMに比べてはるかに少ないものでした。7ナノメートル シュリンクでは、IBMはL3キャッシュにより高速なSRAMを使用しつつ、トランジスタのバジェットもサーマル エンベロープも範囲を超えることのないようにすることができた、とStarke氏は述べています。
言うまでもないことですが、Samsungのファウンドリーで7ナノメートル プロセスの歩留まりが向上すれば、IBMは16番目のコアをアクティベートして、それに対して追加料金を請求できるようになります。もっとも、それが実現するのは、Power10が市場に出てから1年間後、おそらく2022年の後半頃のことだろうと思います。
Power10チップは、2つのHemisphere(領域)に分かれており、それぞれに64MBの独自のL3キャッシュ ブロックと、8個のSMT8コアまたは16個のSMT4コアがあります。これらのコアはすべてL3キャッシュ バスを通じて互いにリンクされており、すべてのコアがどのL3キャッシュ セグメントとも通信できます。分割のしかたに応じてですが、SMT8コアは、それぞれ2MBの専用L2キャッシュを備え、SMT4コアは、それぞれ1MBの専用L2キャッシュを備えています(上のダイの画像はSMT8コア向けにブロック化されていますが、実際のトランジスタは移動しないことに留意してください。SMT8とSMT4は、エッチング後およびパッケージングで設定されて誰も触ることができない、同じハードウェアの2つのモードであるに過ぎません)。
Power10チップの上端部を横断するように並んでいるものや、チップの下端の中央にあるより小さな回路のブロックが何者なのかは、まったく分かりません。見ているものに興奮し過ぎて、これらについて尋ねそびれてしまいました。チップ上にたくさんあるものなので、何かを行っているに違いないでしょう。
チップの下部には2つのブロックがありますが、それぞれが、32GT/秒、16レーンのPCI Express 5.0コントローラーであり、フル デュプレックスでレーンすべて(x16)を使用すると128GB/秒ということになります。これは、2017年末に世界に先駆けてPower9チップ上に登場したPCI Express 4.0の2倍の転送速度です。PCI Express 5.0が32レーンあるというのは、他のサーバーと比較して多いようには思えませんが、思い出してください。IBMにはさらに優れたものがあります。
チップの四隅にあるのが、PowerAXON(旧「BlueLink」)SerDesです。それぞれ、最大32GT/秒を実現する、8レーン(図ではx8)のPowerAXONコントローラーが全部で16あり、合わせて1TB/秒の帯域幅を実現します。これらのPowerAXONリンクは、2、4、8、または16ソケットを持つマシンでNUMAインターコネクトに使用されます。また、永続メモリー、アクセラレーター、およびその他の入出力デバイスへのOpenCAPIリンクでも使用され、また、以下で述べるように、オールメモリー ネットワークに向けてのシステム間での統合されたメモリー クラスタリングにも使用されます。
OpenCAPI Memory Interface(OMI)は、このSerDes設計に対してマイナー チェンジを行ったものであり、また、専用DDR4メモリー コントローラーの後継となるものです。現在、IBMは、Microchip社製のサードパーティ メモリー バッファー チップ(昨年のHot Chipsでプレビュー)を使用して、OMI SerDesがバッファーと高速に通信できるようにし、バッファーがDDR4(現在)またはDDR5(今後)と通信するかどうか決められるようにしています。このように、プロセッサーおよびそのメモリー コントローラーは、より新しいメモリーをサポートするためにアップデートされる必要はありません。それはメモリー スティック上のバッファー チップが行うことです。これは、金銭面(数ドル)でも、遅延の面(使用されている物理メモリーによって、10ナノ秒未満または5%~10%程度の遅延増加)でも、多少、高くつくことになりますが、そのことは、Power10チップは柔軟性が高いということを意味します。これが、たとえば、他のX86またはArmサーバー プロセッサーとの違いです。それらは、物理メモリーにハード コーディングされているため、アップグレードすることはできません。8つのOMI SerDesから成るバンクが、チップの左側と右側にそれぞれ1つずつあり、計16のx8 OMI SerDesで、チップ当たりの帯域幅は1TB/秒となります。ここで重要なことがあります。そのOMI SerDesは、同じプロセスでエッチングされたDDR4メモリー コントローラーと比べて、チップ領域の平方ミリメートル当たりで6倍の帯域幅を実現します。そして、IBMはこのことを承知しています。なぜなら、Power9でDDR4コントローラーを、Power10のアイデアをプロトタイプするためにIBMが使用したPower9'チップでSerDesを取り入れてきたからです。
Power10チップは、最大4TBのDDR4メモリー(3.2GHz以上の動作スピードを前提)をサポートし、ソケット当たりの理論上ピーク帯域幅は最大410GB/秒となります。Power10チップは実に見事な2PBの物理メモリー アドレッシングを備えています。現行のX86チップは最大で64TBの物理アドレッシングです。
ご覧の通り、コアおよびL3キャッシュ ブロックと、PowerAXON、OMI SerDes、PCI Express5.0コントローラーの間には、チップの中央のブロックと、周縁部にあるインターフェース部とのインターフェースを提供する2列の回路があります。
もうひとつ、これはご覧になっても分からないことがあります。PowerAXONコントローラーを介してチップへ入ってくる1TB/秒の帯域幅がありますが、それに加えてPCI Express5.0コントローラーを介しての256GB/秒もあります。これは、メモリーへまたはメモリーからのOMI SerDesを介しての1TB/秒との間でかなりうまくバランスが取れています。
それでは、そのコアについて少し掘り下げてみましょう。
Thompto氏によれば、Power10コアの徹底的なリライトのおかげで、各Power10スレッドは、様々なワークロードにわたってPower9コアに比べて平均で20%パフォーマンスが向上しており、キャッシュ階層の変更のために、平均的なコアは30%パフォーマンスが向上しているとのことです。
以下は、SMT4コアを図式化したものです。
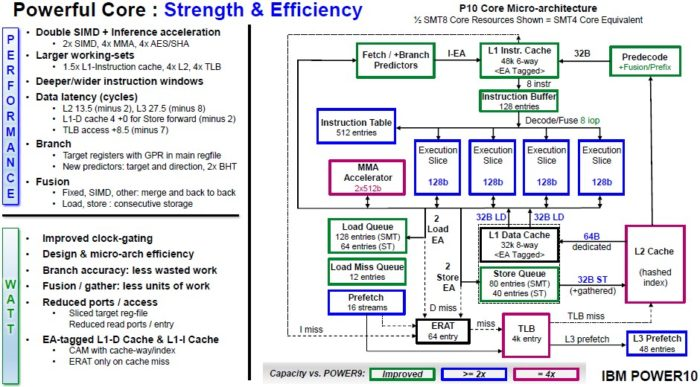
SMT8コアであれば幅が2倍でしょうし、プレゼンテーションにうまく収まりませんでした。Starke氏とThompto氏が示してくれたのがSMT4コアのみだったのはそういう理由です。Power10コアの中央部には、4つの128ビット実行スライスがあります。また、48KBのL1命令キャッシュと32KBのL1データ キャッシュがあります。上図から見て取れるように、Power10コアの機能の多くは、Power9コアの2倍または4倍になっているようですが、あまり向上していないものも、少数ながらあるようです。
興味深い情報があります。IBMによれば、Power10のクロック当たりの処理命令数(IPC)は、Power9に比べて30%向上しているそうです(Power7、Power8、Power9、および現在のPower10チップの設計ポイントとしてIBMが使用する同じ4GHzのクロック スピードに標準化)。シュリンクにより、この処理を半分のワット数で行えるようになり、Power9に比べてワット当たりのパフォーマンスは2.6倍です。ということは、熱設計の観点からは、クロック スピードを4GHzから3.5GHzへ落とし、2つのチップを1つのソケットに入れる余地があるということであり、Power9チップに比べて電力消費量が極めて少ないことを意味します。
そして、これはまさに、IBMが来年に一部のPower10マシン向けに計画していることに他なりません。この点については来週号で取り上げようと思います。










