IBMのRPG向け生成AIコード アシスタント開発に貢献する方法
2023年10月、IBMは、「Project Hopper」 watsonx Code Assistant for Zを発表しました。これは、名前が示す通り、Microsoft社が作成したオープンソースのVS Code統合開発環境に最終的に組み込まれることになり、プログラマーがCOBOLでコーディングされたアプリケーションをJavaに変換するのを支援するように明示的にトレーニングされているプログラミング アシスタントです。 小誌でも、その時期に、IBM iプラットフォームで同じようなこと(あるいは別のこと)を行うために、LLMや生成AIがどのように使用される可能性があるかについて検討を行っています。そして、5月のPOWERUp 2024カンファレンスでは、IBM iプラットフォームのチーフ アーキテクトであるSteve Will氏が、 IBMがRPGアシスト ツールを開発中であることを明らかにしています。
現在、IBMは、コード アシスタント モデルのトレーニングを行うために、RPGコード( 大量のRPGコード )を必要としています。そのため、IBMは、世界中のRPGプログラマーからの支援を切に求めています。このコラムを読んでいるあなたの支援です。
提供されたコードでトレーニングされたAIモデルは、ほぼ間違いなく、Z向けのコード アシスタントのように、RPGコードをJavaに移行するのに使用されることにはならないでしょう(もっとも、顧客の望みとなるのなら、IBMは間違いなく、自社のAIモデルにそうした機能を備えることになるでしょうが)。新たなRPG、COBOL、Java、PHP、およびNode.jsアプリケーション スニペットの生成に役立てることができる、たくさんのIBM i向けコード アシスタントを思い描くことができます。RPG向けのコード アシスタントというのは、以前のRPGコードからモダンなフリー フォームRPGへの翻訳を行うのだろうとずっと思っていました(生成AIプラットフォームの中心にある、大規模言語モデル(LLM)が作成された当初の目的はこうした翻訳を行うためでした)。そして、Will氏はこれまで、こうした考えを支持してきましたし、現在もそうです。
IBMは、具体的にどのようなプランなのかはまだ述べていませんが、たくさんの可能性があります。そうした可能性について、Will氏は5月のPOWERUpの基調講演でそれとなく触れており、先週のウェブキャストでは詳しく論じています(「 IBM i & AI - Strategy & Update」と題するそのウェブキャストは、 こちらの「COMMON Guide Tours 2024」のリンクで公開されています)。以下は、IBMが検討している可能性についての現行のリストです。そして、皆さんから提案があれば、Will氏が作業の優先順位を決める際に、参考になるかもしれません。
IBM iコミュニティ: コード アシストの基礎的機能
IBM iコード アシスト ツールに求められる機能
- プログラマーの既存のRPGでの作業を支援する
- 記述に基づいてモダンなフリーフォーマットILE RPGを生成する
- 既存のコードを調査および説明する
- RPG向けのテスト プログラムを書く
- ...ついでに、古いRPGをモダンなILEベースのフリーフォーマットへ変換する
チーム ロチェスターは、Code Assistant for RPGを作成するのに、数多くの様々なLLMを使用することができました。たとえば、ServiceNow社のStarCoder、AI21labs社のJurassic-2、Aleph Alpha社のLuminous、Microsoft社のPhi-2、およびMeta Platforms社のLlama 2および3などです。しかし、Will氏によれば、IBM iチームは、IBM独自のGranite LLMファミリーを選んだということです。IBMは、Watsonxスタックに、3つの異なる独自のAIモデル ファミリーを持ち、そのスタックには、何十ものその他のオープンソースLLMも含まれています。これらのモデルには、それぞれ変成岩の岩石名にちなんだ名前が付けられています。Slate(粘板岩)モデルは、エンコーダー専用モデル(これは、生成AI向けに使用することはできないが、分類およびエンティティ抽出作業が得意であることを意味します)です。Granite(花崗岩)モデルは、デコーダー専用モデルであり、生成タスク向けにのみ使用されます。そして、Sandstone(砂岩)モデルは、デコーダーおよびエンコーダーAIアプローチの組み合わせを採用し、生成および非生成作業に使用することができます。
Code Assistant for RPGでは新たなコードの生成やコードの変換が重要だと考えて、チーム ロチェスターは、IBM Researchによって開発され、Watsonxスタックに組み込まれているGraniteモデルを使用しています。
Graniteモデルは、数知れないほどのパラメーターにわたってトレーニングされましたが、その数は、実効的には十分多い数であるに違いないものの、IBM Researchがかなり控え目なGPUクラスター(「Vela」と呼ばれる)で実現している以上の性能を要求するほど多くはないと考える必要があります(「Vela」については、 「 The Next Platform 」のこちらの記事を参照)。このマシンは、たった360のノードを持つに過ぎません。それぞれ、8つのNvidia社の「Ampere」 A100 GPUアクセラレーターで、合計2,880個のGPUとなります。それらのGPUは、ピーク64ビット浮動小数点(FP64)性能が27.9ペタフロップス、ピークFP16性能が898.6ペタフロップスで、これはAIモデルをトレーニングするのに有用です(推論向けには、INT8 1/4精度が利用可能であり、スループットは1.8エクサフロップスへと倍増します)。このマシンは、数週間から数か月を掛けて、かなり大規模なモデルを作成するのには十分に大きなマシンです。無理やり見積もってみれば、Graniteのパラメーターは最大で3,000億個くらいではないかと思われます(あるいは4,000億個)。
とはいえ、フルにパラメーターをスパンしてモデルを使用する必要はありません。実際、多くはそうしません。たいていは、そのジョブにとって必要でないからですが、さらに言えば、モデルをトレーニングするのに必要な演算量は、モデルがスパンするパラメーター数に正比例するからです。数兆個のパラメーターが必要な場合は、相当な期間でモデルをトレーニングするために数万個のGPUが必要となります。これには、今日の価格で約10億ドル掛かります。これは、GPUにフィードするのに必要なメモリー容量およびメモリー帯域幅は、トレーニングするデータの量に比例するからです。GPUがより多くのHBMスタックド メモリーを備えている場合は、少なくて済みます。しかし、Micron Technology社、Samsung社、およびSK Hynix社製のGPUメモリーは品薄で高価であるため、AIアクセラレーター メーカー(GPU製造メーカーも含めて)は、可能な限り、メモリーを抑えます。そのため、エンド ユーザーは、そうでなければこれらの非常に高価なデバイスで得られたかもしれない利用率よりも低い利用率になってしまいます。一言、付け加えるなら、入手可能なHBMメモリーで市場を独占できるため、Nvidia社は大儲けです。このような理由で、GPT-4のような大規模なモデルをトレーニングするのには何か月も掛かるというわけです。いずれにしても、お金で払うか時間で払うかです。
Will氏は、RPGプロジェクトがGranite 8Bモデルを使用していると述べています。これは、80億個のパラメーターをスパンしているのみであることを意味します。これはかなり控え目なモデルですが、それは良いことであるのかもしれません。モデルのパラメーターが少なくなれば、推論で必要となる演算はぐっと少なくなります。つまり、おそらくPower10以降のCPUの内部の行列演算ユニットで稼働できるということになるわけです。また、IBMがかなり控え目なクラスターでモデルをトレーニングおよび再トレーニングして、繰り返し時間を掛けてモデルを改善し続けることができるということでもあります。
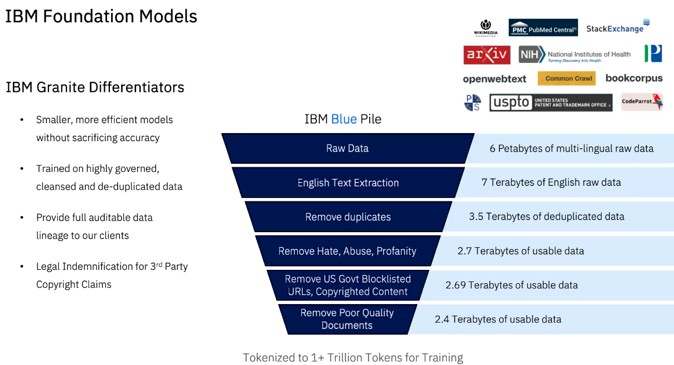
Graniteをトレーニングするのに使用されたデータは、主にインターネットからのものでした。そして、Will氏は、これがどのようにして6 PBの生の多言語データから2.4テラバイトの使用可能なデータへとすべて煮詰められるのかについて述べています。次いで、そのデータは、トレーニング向けに1兆個を超えるトークンへと分割されます(トークンは、単語の一部分で、LLMにおけるデータの単位です)。
大規模言語モデルは、トランスフォーマー モデル(基盤モデルとも)の一種です。これは、大規模なデータのコーパスの統計的重みを使用してトレーニングされ、たとえば、英語から中国語への語句の変換のように、入力データを異なる種類の出力データへ変換するからです。手持ちの最大のクリーンなデータセットおよび多数のパラメーターに対して総当たり式でトレーニングしてから、より精密なデータセットでそのチューニングを精緻化することができます。RPGコードを生成したい場合は、数千億個のパラメーターで事前学習済みのGraniteモデルを使用して、キュレーションされたRPGコードのコーパスを使用して再トレーニングします。そして、コード アシスタントに平易な英語で話し掛けてRPGコードを作成できるようにしたいという場合は、本当に必要になるのは、RPGコードと、そのコードが行う処理についての英語による説明を一対にした大量のデータ ペアなのです。

そして、これこそがまさに、Will氏とIBMの彼の同僚がIBM iコミュニティに提供を依頼しているものに他なりません。IBMは、自前のRPGコード(IBMではRPGコンパイラーの作成や機能強化、コードで行った変更のテストに使用しています)を大量に保有していますが、それよりもっと大量に必要です。また、IBMは、Code Assistant for RPGモデルをトレーニングするための良質なRPGコードを入手するために、IBM iコミュニティのコーディングのレジェンドたちともコンタクトを取ってきました。Susan Gantner氏、John Paris氏、Scott Klement氏、Jim Buck氏、Paul Tuohy氏、Niels Liisberg氏、Yvonne Enselman氏、Mats Lidstrom氏、Koen DeCorte氏、Steve Bradshaw氏といった錚々たる顔ぶれが名前を連ねています。また、この記事の執筆中にも、コード提供は行われています。そして今度は、皆さんの番です。
IBMは、RPGコードだけでなく、RPGコードに関する質問/回答のペアも収集しようとしており、両者についてコードを利用する権利を付与する方法を用意することになります。また、ライセンスは、外部に見られても構わないコードと、Code Assist for RPG向けのモデルのトレーニングの際にIBMに見られるのみのコードとで、区分されることになります。コード提供者が選択して、 https://ibm.github.io/rpg-genai-data/#/にて登録することができます。
IBMは、第3四半期(現在から9月末までの期間)を通じて、RPGコードと、コードと説明のペアを収集します。それから、こうしたデータを使用して、Granite 8B LLMの再トレーニングをもう一頑張りするということになります。
IBMは、Code Assistant for RPGがいつ利用可能になるか、どのようなデリバリー方式になるのか、費用はどれくらいになるかについて、現時点ではまだ決定していないようです。できることなら、お手頃な価格の単なるVS Code向けプラグインという形であってほしいと思います。また、顧客がWatsonxスタックの購入を求められるというようなことは、ないようにしてもらいたいものです。しかし、IBMのマーケッターがWatsonxスタック促進のためにその方向へ向かったとしても驚かないでください。










