DB2 For iのパイプライン・ユーザー定義表関数
パイプは、効率的かつ的を絞ったやり方で物を運ぶのに便利であり、素晴らしい発明だと思います。下水の移送、オイル運搬、アヒルの瓶詰め (Ace Novelty社の「Pipe Full of Fun Kit #7」をフィーチャーした「The High and the Flighty」Foghorn Leghorn 漫画を覚えている年代の方なら) いずれの場合も、我々の世界はそれがなくては成り立ちません。
それに遅れをとるまいと、IBM i 7.1 TR9 および IBM i 7.2 TR1 から DB2 for i は、行をユーザー定義の表関数 (UDTF) の結果セットに素早く登録する「PIPE」ステートメントを提供するようになりました。
パイプライン関数を作成するのは簡単で、非パイプライン SQL 表関数の作成によく似ています。簡単な例として、アプリケーションのコード・ベース全体で頻繁に参照される一連の関連グローバル変数があるとしましょう。

一般的に、アプリケーションでこれらの変数に簡単にアクセスできるようにするためアプローチとしては、それらを一挙に一掴みにして、単一行で返す表関数を作成します。

新しい PIPE ステートメントでは、これを別の方法でコーディングしています。

おわかりのように PIPE は単に行を表関数の結果セットに挿入しているだけです。当然、PIPE ステートメントで渡された値およびデータ型の数は、 UDTF の return 表定義と互換性がなければなりません。
では、PIPE ステートメントは、 DB2 コーダーにとってどのようなメリットがあるのでしょうか? まず、構文がわかりやすいです。次に、PIPE がメリットがあるのは、変数 (表データではない) が UDTF のデータを支える原動力となっている場合です。PIPE のメリットがない場合、変数データは一時表に保存するか、SELECT ステートメントに組み込む必要があります。(UDTF が既存の表の標準クエリーを利用する場合、パイプライン関数を使用する必要はおそらくないでしょう。)
以下の COUNTER 表関数は、任意の数の整数値を返すことで PIPE のメリットを図示しています。

パイプライン UDTF を呼び出します。
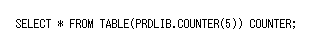
以下の結果セットを返します。
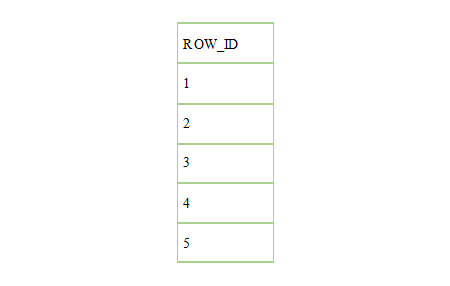
この COUNTER UDTF は、再帰的共通表式でも実装できますが、私の意見ではパイプライン関数の方が簡単にフォローできます。
いつもどおり、UDTF を作成して受信できると思われる平均行数を DB2 に推測させる場合に、計数値を指定します。
パイプライン SQL UDTF の作成は、外部 UDTF の作成に似ているという考えは正解です。両方とも一度に1 行ずつ UDTF 結果セットに挿入します。最後に、外部 UDTF は、 PIPE のように行データとして変数のみ返すことができます。
最後の例については、以下の ParseData 表関数は、指定された区切り文字に基づいてテキスト・データを分割し、結果を行として返すパイプライン関数です。おわかりのように、新しい行はそれぞれ、まず一時表にダンプする代わりに、PIPE から直接送信されます。

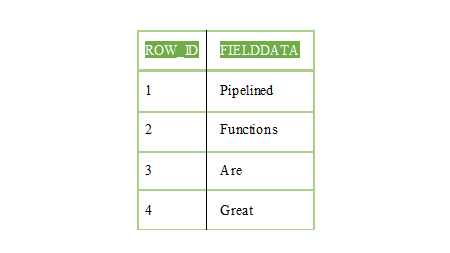
ParseData 関数の利用法の例を示します。

出力は以下のようになります。
パイプライン SQL 表関数と外部表関数の間には類似性があるため、IBM の Scott Forstie が私のために解決してくれましたが、私が外部 UDTF に対して持っていた懸念に対処したも同然です。最近まで、V5R2 の初期の外部 UDTF での経験に基づいて、すべての外部 UDTF は影で一時 (QTEMP) 表を作成するため、比較的遅いのだと思っていました。Scott は、一時表の問題は、SQE ではなく CQE を通して外部 UDTF を処理した場合のみ該当すると答えてくれました。現在は、ほとんどの SQL ステートメントは SQE で処理されているため、これが問題になることはないでしょう。
パフォーマンス面では、パイプライン関数は、一時表を使用して作成された類似の UDTF と比べてもメリットがあると言えます。Forstie が「小さな一時表がメモリーに詰まっていたとしても、PIPE ステートメントにはパフォーマンス面の利点があります。ライブラリー管理、ファイル管理、カタログ管理のオーバーヘッドを避けることができるためです」と言っています。パフォーマンス面のメリットは、どれだけ頻繁に関数が呼び出されるかに大きく依存します。
パイプライン UDTF は DB2 for i 開発者にとっての資産です。実行性能がアップし、コーディングが簡単になり、IBM i 開発者に他の DB2 バージョンで利用できる別の機能を提供できる可能性があるためです。
Michael Sansoterra: 米国ミシガン州、Grand Rapids にある Broadway Systems の DBA。Mike への質問やコメントは IT Jungle Contact ページからお願いいたします。










