IBM i のウンチクを語ろう:その115
- Powerプロセッサの発展とSpyre -
皆さん、こんにちは。IBM i の2025年はProject Bobの始まりの年だった、と言われるようになるのかもしれません。実際にこのコラムにおいても、生成AIに始まりwatsonx Code Assistant for i を経て、Project Bobへと至るテーマを何度か取り上げています。ユーザーの方と話していても、スキルや人材の不足、あるいはそれらが原因で停滞している古いアプリケーションの見直しや刷新、といった長年の課題を一気に解消する決定打になるかもしれない、という期待の高まりを肌で感じます。あとは料金体系や技術的な詳細発表を待つばかり、といったところでしょうか。IBMの方々も私達の期待を理解してくれていると信じておりますが、くれぐれも料金的に「高嶺の花」にはならないことを願っています。
Bobの陰に隠れてしまった感がありますが、新しいプロセッサであるPower11と、その周辺テクノロジーのSpyreアクセラレータももう一つの大きな革新です。これらの登場は単にCPW値を引き上げるだけではなく、今後のシステムのあり方を見据えたものであることは言うまでもありません。背景にあるのはやはりAIの浸透です。今回はプロセッサの性能向上策のトレンドを見ながら、Spyreは何を目的として登場したのか、どのように位置付けられるのか、について考えてみたいと思います。
何事であれ将来を見極めるための効果的なアプローチの一つは、歴史を学ぶことだと良く言われます。では世界初のマイクロ・プロセッサは何なのかと言うと、1971年に登場した4ビット、クロック周波数500-741KHzのIntel 4004だとされています。用途は日本のビジコン社製電卓の心臓部であり、4ビットあれば16種類のデータ、すなわち数字・小数点や他の演算記号を取り扱えます。その後のプロセッサの発展は、いくつかの観点から捉えることができます。
その一つは一度に取り扱えるデータ種類の拡大です。4ビットの後は世代を経る毎にビット数が倍々になっており、現在の汎用プロセッサの主流は64ビットであることはご存知のことと思います。4ビット・プロセッサであっても、やろうと思えば何度かの処理を繰り返すことでどのようなデータでも取り扱うことはできますが、非効率であり現実的ではありません。そして4ビットが8ビットに拡張されると、アルファベットなどのシングル・バイト文字を取り扱えるようになります。16ビットだと日本語などのダブル・バイト文字、32ビットで小数(単精度浮動小数点数)やあらゆるタイプの文字、と拡大します。ご存知ユニコードのUTF-16は、2ないし4バイト、すなわち16ないし32ビットの表現形式ですね。64ビットになると倍精度の浮動小数点数、さらに実際に必要性があるのかどうかわかりませんが、IEEE 754(Wikipediaへのリンク)と呼ばれる仕様においては、128ビットの四倍精度の浮動小数点数も定められているそうです。このような動きと連動して、取り扱えるメモリ空間も拡大します。
もう一つはパフォーマンス向上であり、かつてはクロックの高速化がその主な原動力になっていました。Powerプロセッサもその例外ではなく、初代が登場した1990年以来高速化は続き、2007年にリリースされたPower6の5GHzをもってピークを迎えます。以降の、例えば最新のPower11の最速クロックは4.4GHzと、一見ダウングレードされています。プロセッサ登場以来継続されてきた、クロック高速化追求の時代は2007年をもって終焉を迎えているのです。
当時の資料を眺めてみると、クロック高速化はプロセッサの高密度化や、搭載されているトランジスタの微細化によってもたらされたことがわかります。世代を経る毎に小さくなる、製造技術のナノ・メートル(nm)という値をよく目にしますね。トランジスタは言わばスイッチなので、小型化すればこれを切り替えるエネルギーは小さくなる、すなわちクロック・スピードを上げやすくなります。2004年当時は数年以内にクロック・スピードは10GHzに達するだろうとの業界予測があったそうです。ところが微細化には副作用があって、一定割合の漏れ電流は防ぎようが無く、プロセッサは電熱器のように発熱し、自らを破壊させてしまいかねません。結果的に5GHzは消費電力・発熱量の壁として立ちはだかり、クロック高速化の方針は転換しなければならなくなりました。
IBM Powerより前のAS/400用プロセッサにおいては、もっと早いタイミングで乗り越えなければならない別の壁がありました。あまり知られていなかったその名称は「IMPI」(Internal MicroProgrammed Interface)と呼ばれており、CISC(Complex Instruction Set Computer: 複雑命令セットコンピュータ)タイプのものでした。基幹業務をサポートする上で必要になる、各種の複雑な命令セットをサポートしていたのですが、内部の制御回路が複雑だったためにクロック高速化が困難でした。そのために1995年に制御回路がシンプルなRISC(Reduced Instruction Set Computer)タイプに切り替えるという大転換を図りました。このあたりの経緯は、当コラム「過去30年の間に最も大きく変わったもの」のPart1とPart2にてお話していますので、よろしければ目を通してみてください。
さて、クロック高速化に代わってパフォーマンスを追求する原動力になったのは、トランジスタの微細化・集積度向上を背景にした複数コア化です。手元の記録によると、例えば2010年に登場したPower7のソケットあたり最大コア数は8だったのに対して、2025年の最新のPower11ではスペアを除いて30と4倍近くになっています。そしてプロセッサ全体の処理能力が向上するならば、それに応じた量のデータを外部から遅滞なく供給しなければなりません。さもないとせっかくの高性能プロセッサは「遊んで」しまいます。
Power11の前提条件の一つに、メモリ・デバイスはDDR5タイプでなければならないというものがありますね。これに加えてメモリ・バスの高速化やメモリ用バッファの見直しなどがなされ、ソケットあたりの帯域幅は、従来のPower10とDDR4の組み合わせに対して3倍の1200GB/sに強化されています。このようにプロセッサ単体に留まらず、周辺のハードウェアやマイクロコードなどを含むシステム全体にわたってバランスを保ちながら強化できるのは、IBMならではの強みではないかと思います。
既にお気付きの方もいらっしゃると思いますが、コア数増加が効果的なのは、オンライン処理のようなマルチ・スレッド・ワークロードに対してであって、バッチ処理において典型的に見られるシングル・スレッド・ワークロードは、コアそのもののパフォーマンスが向上しなければ恩恵を受けません。IBM i の性能の指標として用いられるCPW値を大きくするのは間違いないのですが、それだけではバッチ処理のパフォーマンスを判断できないというわけです。この点はシステム構成を決定する際に、忘れてはならないポイントだと思います。そもそもCPWはオンライン業務を前提とした相対性能比です。
さて、クロックの高速化は頭打ち、複数コア化も効果は期待できずという状況下では、シングル・スレッド・ワークロードのパフォーマンスが向上する可能性は閉ざされているのでしょうか。これに対する解の一つとして、特定のアプリケーションに特化した、専用のハードウェアを用意する方法があります。何かの処理を行う際に、ソフトウェアではなくハードウェアの階層で実行した方が高速だからであり、その典型はAIアプリケーションです。NVIDIA社の基幹製品として有名なGPU(Graphics Processing Unit)と呼ばれる特殊なプロセッサや、Power11プロセッサ内蔵のMMA(Matrix Math Accelerator)回路、またはIBM Power用のSpyreと呼ばれるオプションカードがそれに該当し、これらは一括りにアクセラレータと称されています。似たようなモノではあるのですが、用途が異なっています。ちなみにIBMではSpyreを、AIU(Artificial Intelligence Unit)と呼んでいます。
AIアプリケーションには学習と推論と二つのフェーズがあります。そして学習フェーズにおいては精度の高いデータで大量の演算を行う必要がありますが、推論フェーズでは低精度のデータを対象とする比較的少量の演算でも十分に実用になる、という事実があります。例えば以下の粗い画像を見た時に、私達はレオナルドダヴィンチ作のモナリザだと判断できますが、
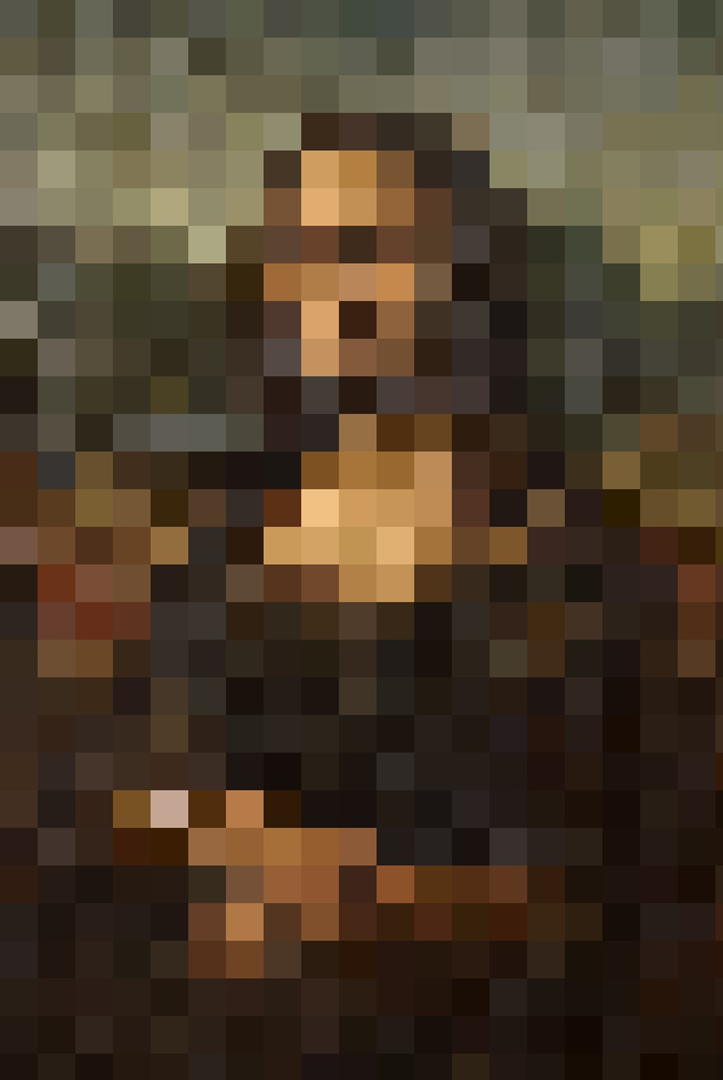

アクセラレータの中でもパフォーマンスに優れるGPUで学習し、やや劣るSpyreで推論を行う、というのが想定されているシナリオです。もう少し詳しく見てみましょう。
GPUは高額で消費電力量も大きいので、個人は言うまでもなく、ユーザー企業が購入するにはハードルはかなり高いものになるので、データ・センターに設置された環境をクラウド・サービスとして利用するのが一般的だと思います。精度の高い大量のデータを用いますが、学習フェーズにあるのでリアルタイム性はあまり強くは求められません。そしてその後の学習済みデータを活かした実践の場、すなわち推論フェーズになると、粗い画像のように精度が低いデータを対象に計算量を抑制することができる一方で、リアルタイム性が求められるようになります。また、データ・プライバシー、すなわち業務データの安全性を担保しなければなりませんので、インターネット越しのデータ・センターよりも、オンプレミスの方が望ましい利用環境です。そのためにはコストと消費電力量は抑制されたものでなくてはなりません。ここにSpyreがハマるというわけです。
これまでのプロセッサは、ビット数を拡大する一方で、クロックの高速化とそれに続くマルチ・コア化と発展してきたことがわかりました。今後はメモリのバンド幅拡大と、特にAIを意識したアクセラレータの拡充・強化が進むのでしょうか。私達の生活の中にAIが浸透するにつれ、Spyre以外のアクセラレータも既に身近な存在になりつつあるようです。iPhone用プロセッサ内のNeural Acceleratorや、Copilot+ PC に搭載されるNPU(Neural Processing Unit)などがありますね。今後のビジネスや日常生活はどう変わってゆくのか、楽しみが一つ増えたような気がします。
ではまた











