IBM技術ブログ Vol.8 - IBM i パフォーマンス分析方法 -
IBM i はOSレベルで非常に細かくパフォーマンスデータを取得するための仕組みが組み込みされています。その中にはCPU,メモリ,ストレージ、ネットワークアダプター等の基本的な使用状況の他にアプリケーション的なオブジェクトのロック状況に加えて、IBM i では「待機」と称されるハードウェアリソースの競合による待ち時間も測定、可視化が可能です。(図1)
あるアプリケーションやシステム全体のパフォーマンス(具体的にはレスポンス時間やスループット)が期待値に達しない場合、一般にはシステムリソースの追加を検討する事が多いと思われますが待機の状況によってCPUのコアを増やすべきなのか、より高速なプロセッサーに更新しないと改善されないのか、あるいはアプリケーション的に処理を改善しないといけないのか、等の指針を得ることができます。
IBM i のパフォーマンスデータ収集機能 収集サービス
IBM i OS標準のパフォーマンスデータ収集機能は収集サービスと呼ばれます。収集サービスはOS標準機能なので追加のライセンスプログラムを導入する必要はありません。V6.1以前は収集サービスは手動で開始する必要がありましたが、IBM i 7.1以降では基本的には自動で開始されていることが多いと思います。QSYSWRKサブシステム配下でQYPSSTRCOL という自動開始ジョブが収集サービスを実行しています。(図2)
手動で収集開始・停止することもできます。この場合は、STRPFRCOLコマンド/ENDPFRCOLコマンドを使用します。
収集サービスで取得されたパフォーマンスデータは*MGTCOLというオブジェクトタイプで保管されます。(デフォルトではQPFRDATAライブラリーに格納されます。)
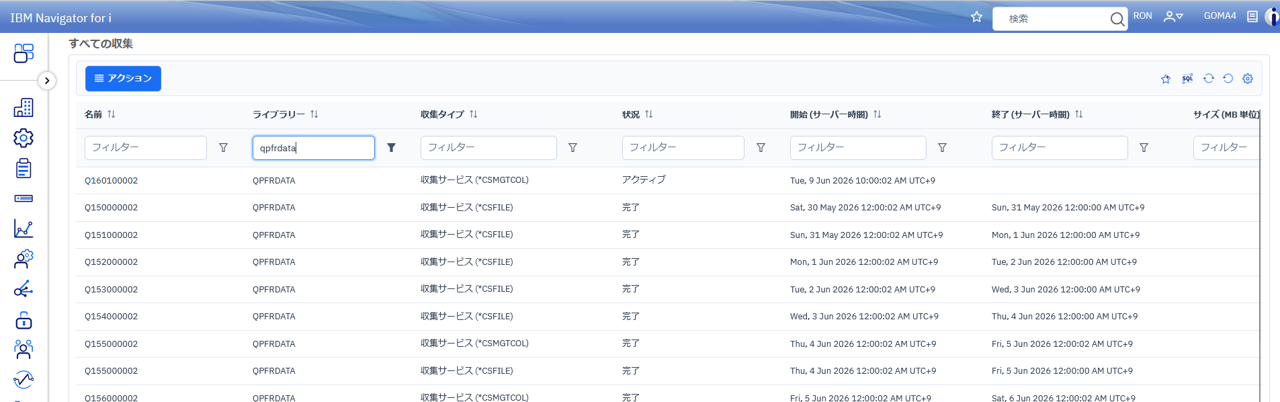
*MGTCOLオブジェクトは取集した生データなため、CRTPFRDTAコマンドでNavigator for i (ほか)で利用可能なデータに展開する必要があります。下記の図3はNavigator for i で収集サービスのデータを表示した例ですが、3カラム目の収集タイプがCSMGTCOLとあるのが収集サービスの生データ、*CSFILEとあるのが展開したデータです。
Navigator for i を使ったパフォーマンスデータの分析方法
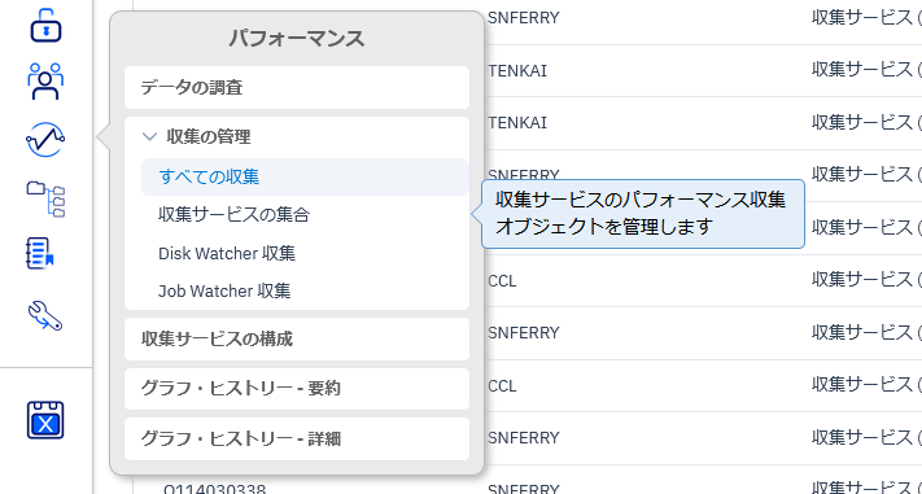
かつては5250画面からSTRPFRTコマンドでレポートをスプール出力して必要なデータを拾う形でしたが、現代的には受け入れられない難解さではないかと思います。現在ではNavigator for i のGUI画面で分析するのが推奨です。すでに無償化されている5770PT1 Performance tools for i を導入するとNavigator for i から以下のようなメニューを表示する事が出来ます。一般には すべての収集 からデータの分析を開始します。(図4)
パフォーマンスデータの分析を開始するには、図3の画面から分析対象の収集サービス(タイプ *CSFILE)を選択して、アクションメニューからパフォーマンスデータの調査を選択します。または右クリックでも選択できます)(図4)
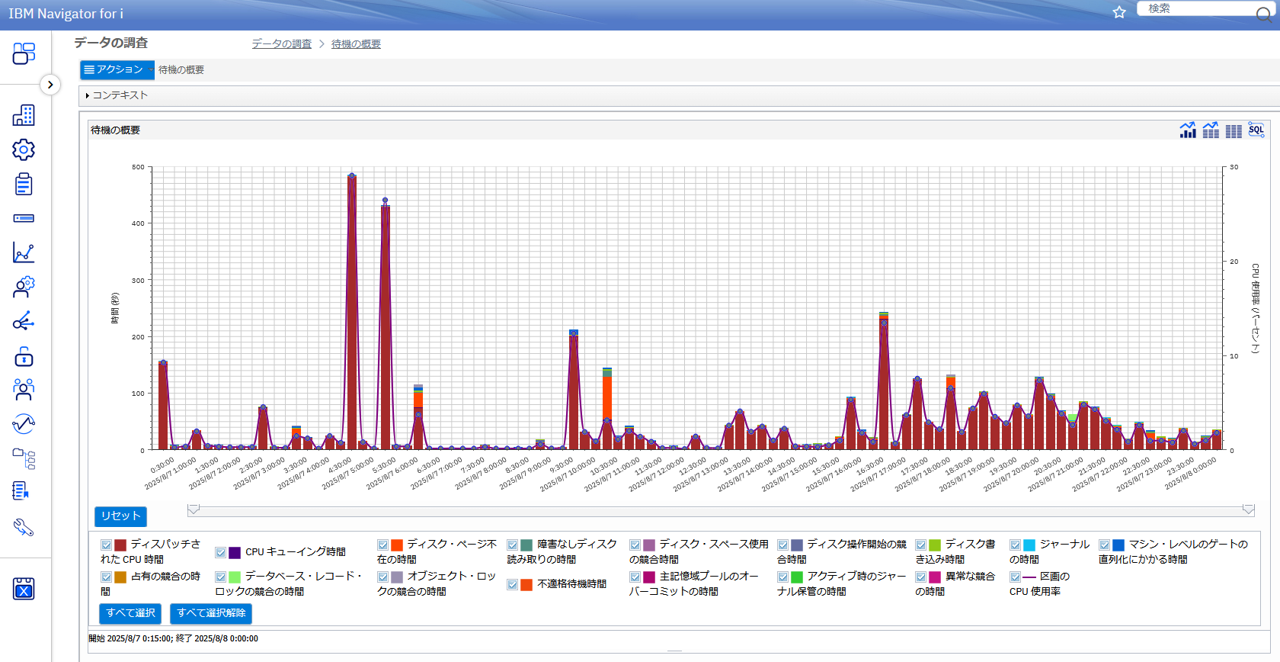
デフォルトでは以下の様にCPU使用率および待機の概要 というグラフが表示されます。(図5)
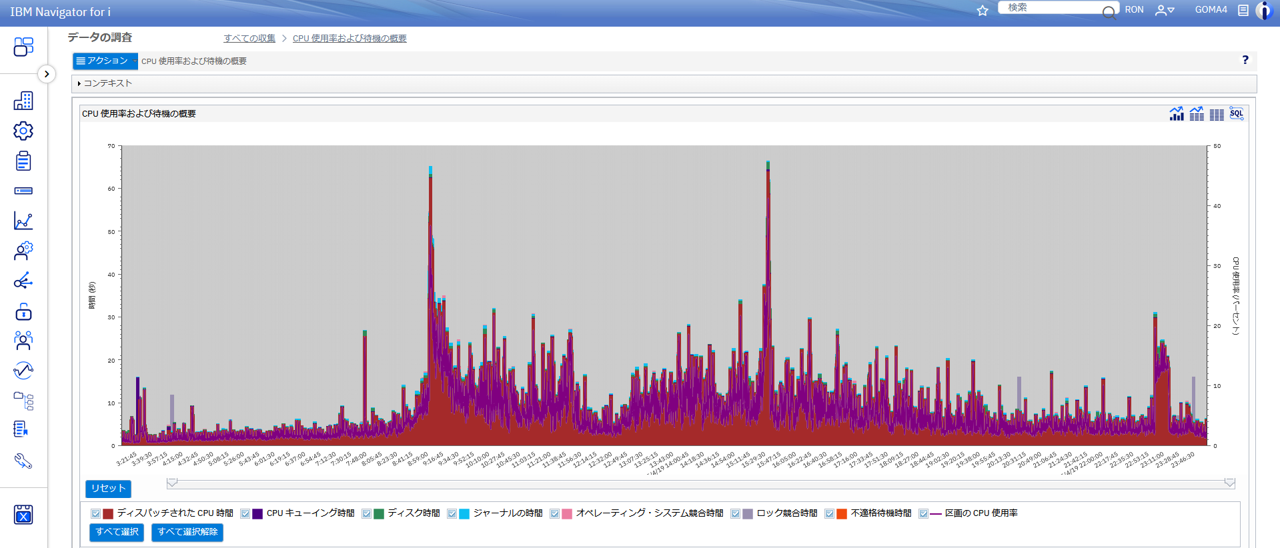
収集サービスで取得したデータは数日分が1つのファイルになっていることもあるため、必要な場合には画面上部にあるコンテキストで分析対象のデータを切り替えることができます。(図6)

これ以降の分析手順は基本的にはケースバイケースとなります。もし特定のジョブやプログラムが遅い、CPU使用率の高い時点の処理状況を調査したい、といった個々の条件に合わせた分析を進めます。
この際、Navigator for i のパフォーマンスデータ分析機能(Performance Data Investigatorと呼ばれます)は実にたくさんの標準提供のグラフ・分析チャートを用意しています。
代表的によく使われるグラフや指標は上記図5のアクションメニューから表示させることができます。(図7)
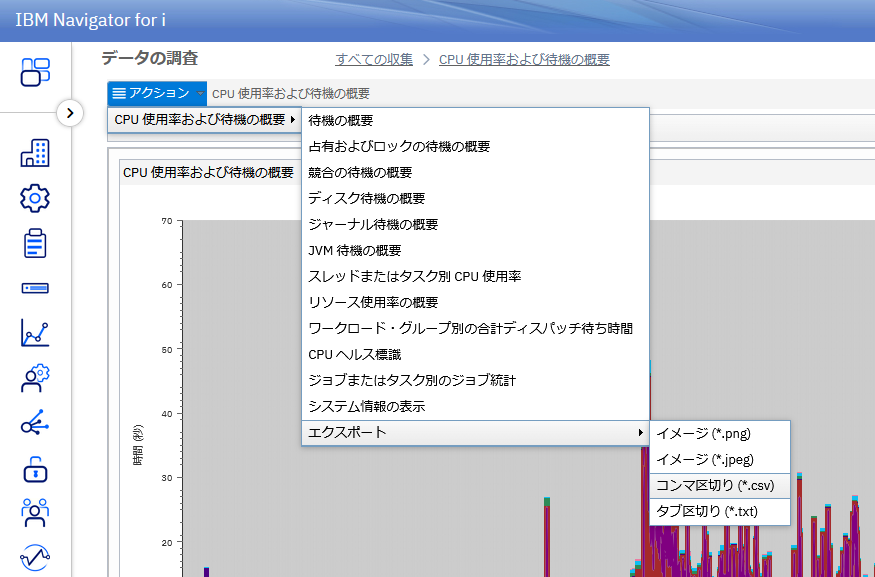
また、Navigator for i では基本グラフでデータを表示しますがcsvやテキストでエキスポートも可能です。
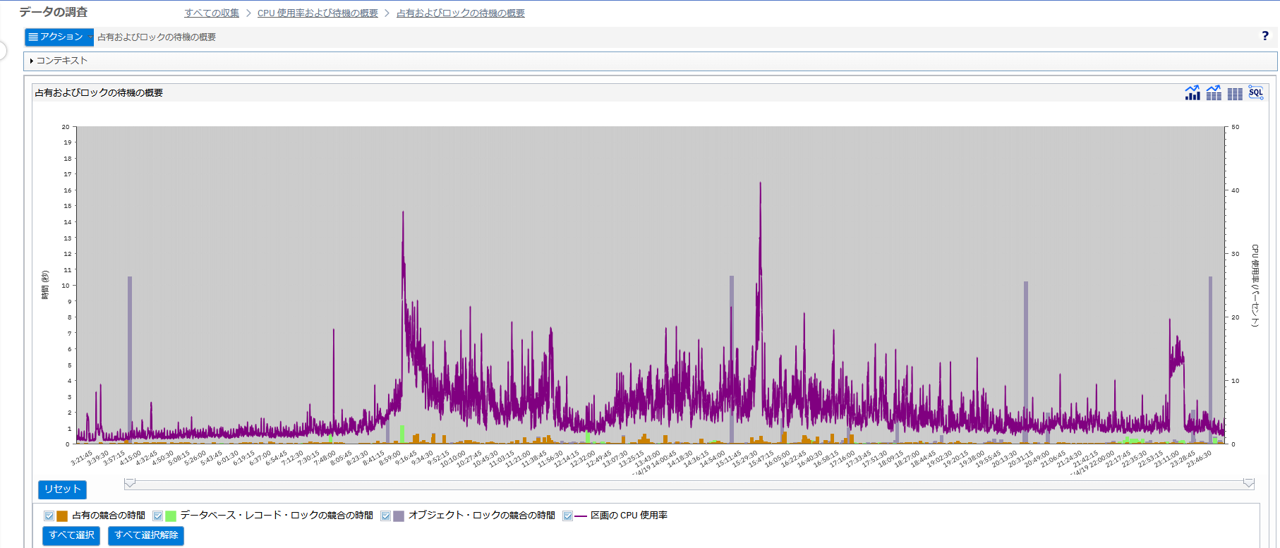
以下は図7で占有およびロックの待機概要 を選択し表示した例です。(図8)
上記図7で表示された深掘りするためのグラフは実はほんの一例です。全ての分析グラフ、指標を表示するには、下記の様にNavigator for i の左側のメニューバーから データの調査 を選択します。(図9)
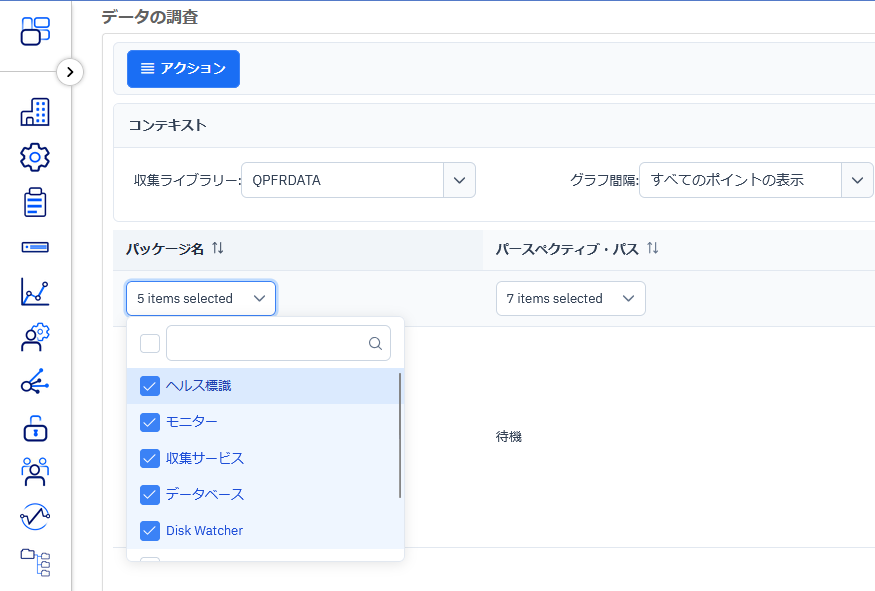
図9の結果、以下のような画面が表示されます。表中のパッケージ名をクリックすると、表示させるグラフ・指標軸のカテゴリーを追加する事が出来ます。(図10)
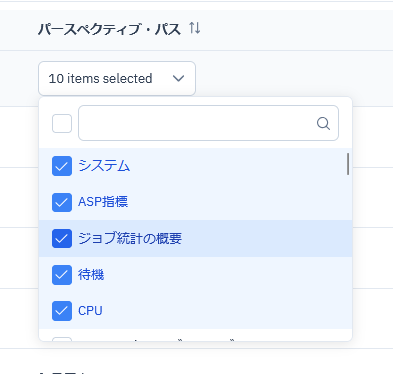
同様にパースペクティブ・パス 欄もクリックすると表示するカテゴリーを追加する事が出来ます。(図11)
この記事で全てをご紹介する事は難しい為、最も簡単な例として、ヘルス標識を使った分析方法を紹介します。
ヘルス標識とは
図12がヘルス標識の例です。CPU,ストレージ、メモリ、5250応答時間の軸で緑・黄・赤で収集したデータが表示されます。赤はそれぞれのリソースの閾値に対し超えているデータ、黄色は閾値と同程度、緑は閾値未満のデータの時間を表します。
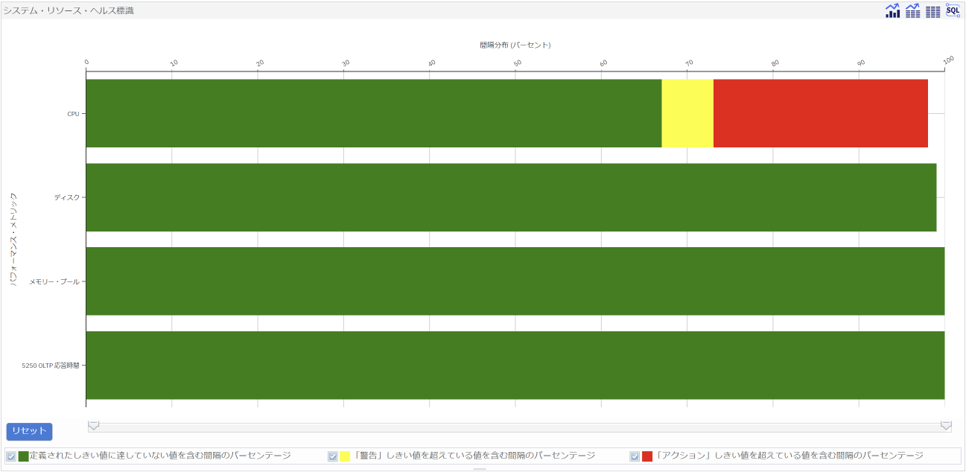
どのプログラムが遅い、どの時間帯の処理を改善したい、といった具体的なパフォーマンス分析の対象が特定されない場合、このヘルス標識で見当をつけることができます。
上記の例ではCPUが閾値越えをしているデータが多いので、さらにCPUについての深掘りしたデータを CPUヘルス標識 で表示できます。図13
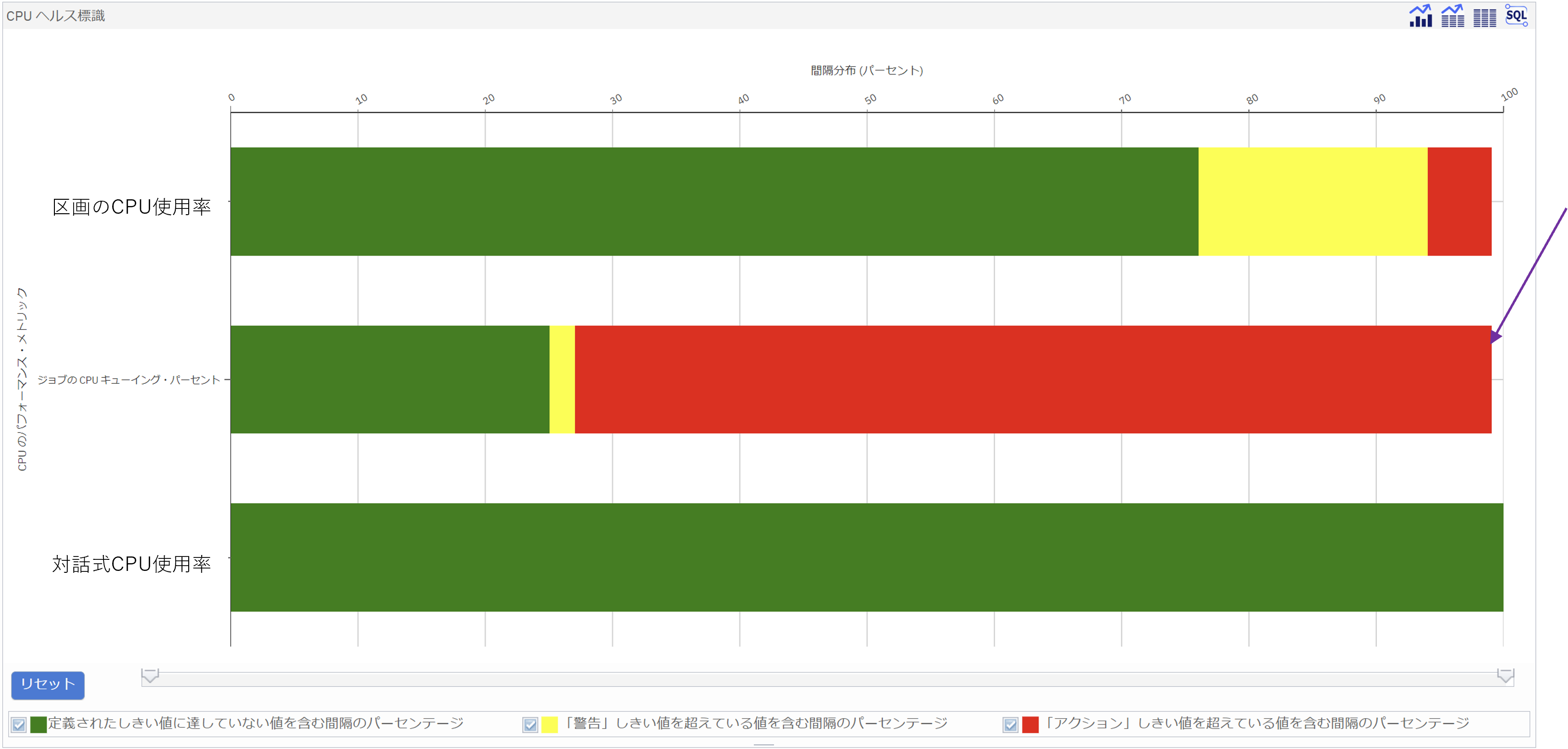
CPUヘルス標識のグラフは3つあります。上からCPU使用率、ジョブのキューイングパーセント、対話型CPU使用率です。今回のグラフではCPU使用率が閾値越え(90%以上)は6%強、閾値(85~90%)は20%弱でしたがそれよりも、キューイングの閾値越え(20%以上)が72%程度というデータが注目されます。つまりCPU使用率が高い事がパフォーマンスが悪い原因ではなく、CPUキューイング時間が長い=実行ジョブ数に対して使用できるプロセッサー数が少なすぎてCPUキューで処理待ちで滞留している時間が大きいという事がわかりました。
このケースではCPUのコア数を増強する、というのが最も適切な解決策と言えます。或いはより高速な新世代のプロセッサーへ移行するのも一案という事が言えます。
執筆者紹介
 |
佐々木 幹雄(ささき みきお) 日本アイ・ビー・エム株式会社 Powerエキスパートラボ シニアITスペシャリスト 2011年:クライアントIT推進部 ITアーキテクトとして中部以西のお客様を担当 2017年:Powerテクニカルセールス 全国のIBM i ユーザー様を担当 2026年:Powerエキスパートラボ 先進ソリューション開発・構築を担当 |










