AIは、IBM i サーバー上で稼働している。今、この瞬間も。
AI(人工知能)は、IBM i に影響を及ぼすかもしれない未来のテクノロジーとみなされることがよくありますが、それはあくまで未来の出来事であり、AIがIBM i にとって重要になるのは、たぶん、空飛ぶ車や動く歩道が登場する頃のことだろうと考えられていました。ところが、IBMのクラウドおよびAIアーキテクトによる最新のPOWERUpのプレゼンテーションで示されたように、AIは、IBM i サーバー上ですでに稼働しており、また、今、この瞬間も動いているのです。
IBM Client Center Montpellier(フランス)のクラウドおよびAIアーキテクト、Benoit Marolleau氏は、「Smarter IBM i Applications Made Easy with AI(AIによって簡便化されるよりスマートなIBM i アプリケーション)」と題するPOWERUpのプレゼンテーションで、どのようにしたらAIテクノロジーを採用してアプリケーションを強化することができるのかについて、IBM i のショップはそろそろ模索し始めるべきだと訴えています。
最初に、Marolleau氏は、AIは空想的な未来のテクノロジーという概念を払拭しようとしました。実際、私たちはAIに囲まれているのだと彼は述べています。「AIは至る所にあります」と彼は述べます。「アプリケーションを使用しているときには、ユーザーのエクスペリエンスをカスタマイズするためにレコメンデーション エンジンが使用されています。今日の目的は、まさにそのようなユーザー エクスペリエンスを向上させることにあります。」
Netflixで番組を探したり、スピード違反切符の回避のためにWaseを利用したりしたことがある人は皆、AIの恩恵を受けてきたことになります。Netflix社やGoogle社(Waze社のオーナー)が、当代一流のデータ サイエンティストを雇う余裕がある巨大テクノロジー企業であることは言うまでもありません。確かに、AIは、平均的な中小規模のIBM i 顧客の枠を超えるものなのかもしれません。

焦ることはありません。AIの魔法はかなり効いているようです。たとえば、最大のニューラル ネットワーク モデルが実際どのように動作しているのか、誰もきちんと正確に説明することができないということからすると、やはり魔法なのかという気もしてきます。ただし、その一方で、AIへの参入障壁は驚くほど低いのです。これは、先人たちによってAI技術に注ぎ込まれてきたすべての労力や、オープンソースの奇跡のおかげでもあります。私たちは、AIという巨人の肩に乗る矮人となることができて実に幸運だということです。
「IBM i には、AIを稼働するのに必要なテクノロジーがすべて備わっています」とMarolleau氏は述べています。「Db2 for iにはデータがあります。中核的なビジネス アプリケーションもあります。IBM i には、ますます多くのオープンソース テクノロジーが導入されています。Power Systemsでは、片やAIモデル、片や予測モデルを構築するテクノロジーが導入されています。そして、先日、IBMは、Power10サーバーを発表しました」 Power10サーバーには、MLトレーニング ワークロードを5倍以上高速化することができるMatrix Math Acceleration(MMA)と呼ばれるものが搭載されています。
IBM i の領域でAIを応用する方法はいろいろあります。IBM i の領域では、IT(情報技術)を応用することそれ自体ではなく、ITを応用することの実用性が常に重んじられてきました。「それは、より少ない資源でより多くのことを行うときのやり方です」とMarolleau氏は述べます。
IBM i のショップに関連性がありそうなAIアプリケーションの例としては、不正検知、顧客離脱予測、および予知保全などがあります。これらのケースでは、機械学習モデルは、ERPやCRMデータベースに格納されている高度に構造化された表形式データでトレーニングすることができます。これらは伝統的な機械学習アプリケーションですが、その他にも、構造化されていないデータを使用するAIの例があります。
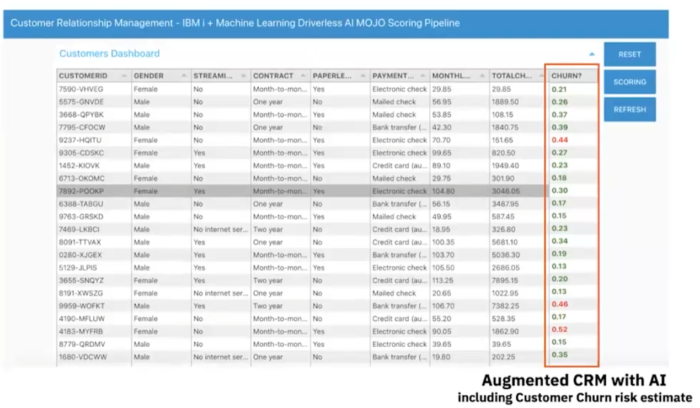
たとえば、自然言語処理(NLP)というものがあります。これはディープ ラーニングの手法を使用して、人間が書いた文章を理解したり、さらには自分で数語から成る文を組み立てたりする機能を探り出すAIの一形態です。NLPを応用する方法のひとつの例として、企業が自社のデータベースおよびファイル システムに保存してきたすべてのナレッジを基にナレッジベースを構築して、そのナレッジベースをERPまたはビジネス アプリケーションへエクスポーズするというものがあるとMarolleau氏は述べています。
もうひとつのNLPの利用法は、ハンブル チャットボットでの利用です。これは、基本的には、そうしたナレッジベースを外部へエクスポーズするプログラムだと言えます。このチャットボットでは、AIの魔力は、顧客からの問い合わせの核心部分を理解する能力と、その後ユーザーに応答を返すことの両方を通じて生み出されます。ちなみにこれは、ほぼ、伝統的検索エンジンのユース ケースです。「多くの顧客がチャットボットを使用されています」とMarolleau氏は述べます。
ディープ ラーニングを使用している、別の主要なAIの形態に、コンピューター ビジョンがあります。コンピューター ビジョンは、実質的には、物体検出および物体識別の目的でカメラから撮影された画像に応用されるAIです。また、顔認識は、今日、幅広く利用されている別の形のコンピューター ビジョンです。
Marolleau氏はプレゼンテーションの際に、AIアプリケーションを開発するために必要となるものについての短いデモを実演しました。彼は見るからにツールを熟知しているようで、簡単に使えそうだと思わせてしまうほどでした。しかし、彼が伝えた重要なメッセージは、それらのツールは平均的なIBM i プロフェッショナルがすぐに入手でき、使い方もそれほど難しくないということでした。そして何よりも、機械学習はロケット サイエンスのように難解なものではないということです(実際、データ サイエンスであるに過ぎません)。
「念のために言っておけば、機械学習は新しいものではないのです」とMarolleau氏は述べます。「生まれは1950年代です。先に述べたように、機械学習はデータから学びます。数多くの例、データベース内の行の例、数多くの列がなければなりません。複雑な事象を観察しているからです。一般に、ビジネスというものは複雑なのです。」
良い知らせは、IBM i で機械学習を開発するために必要とされるソフトウェアの大半は無償で入手でき、オープンソースであるということです。また、データについての知識や、ある程度の専門技能は必要ですが、機械学習をビジネスに応用するのに、本格的なNetflixレベルのデータ サイエンティストである必要はありません。
「心配ありません。たいていの場合、機会学習アルゴリズムを実装することはありません。Pythonのライブラリーを利用するからです」とMarolleau氏は述べます。「それは、トレーニング時にユーザーのエクスペリエンスを使用するアルゴリズムであるに過ぎません。それをベースにして、トレーニングが完了したら、そのモデルは使用可能となり、既存のアプリケーションに統合される準備完了ということになります。」
IBM i は、すぐにデプロイ可能な、最も一般的な数多くの機会学習アルゴリズムが含まれている数多くPythonライブラリーをすでにサポートしています。scikit-learnは、おそらく、最もよく知られているPythonデータ サイエンス ライブラリーです。他にも、NumPyやSciPyがあります。これらのツールは、
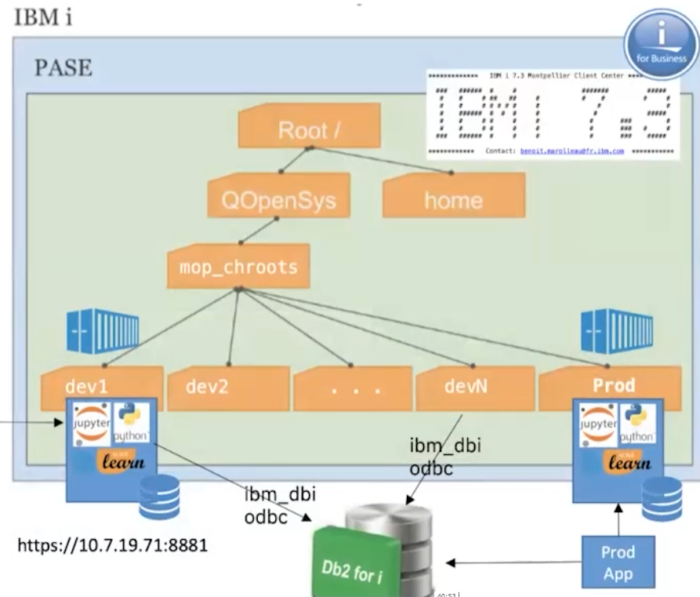
Marolleau氏は開発者に、Jupyter Notebookを使用してIBM iデータをいじってみたり、それらを使用して機械学習モデルを構築してみたりすることを推奨しています。「Jupyterは、Python Package Managerを使用してインストールすることができます」と彼は述べています。「グラフィカルにコーディングでき、IBM i 上のPython向けの統合化IDEとなります。」
機械学習モデルを開発するもうひとつの方法は、AutoMLツールを使用することだとMarolleau氏は述べています。AutoMLツールは、ユーザーに代わって、数多くの詳細項目(パラメーター調整やフィーチャー選択など)を処理してくれます。 H2O.ai 社のDriverless AIパッケージなど、Power Systemsとともに稼働するAutoMLオファリングがいくつかあります(H2O社は、最もポピュラーなオープンソースの機械学習ライブラリーの1つの開発元でもあります)。また、IBMは、AutoAI搭載のWatson Studioも提供しています。また、アナリティクス パワーハウスの SAS 社も、Viyaオファリングで、Power Systems互換のAutoML機能を開発しています。
ユーザーは、IBM i 上で新たなモデルのトレーニング行うことができますが、それを行うために他のプラットフォーム(Linuxなど)を選ぶユーザーも多いようです。新たなPower10チップは、トレーニング時間を短縮するオンボードのMMAアクセラレーターを搭載しています。また、特に、非常に大規模なデータ セットを必要とするディープ ラーニング モデルでは、GPUも、機械学習モデルをトレーニングするための人気の高いリソースです。
トレーニングが完了したら、完了したモデルは、IBM i へ転送することができ、そこで推論用に使用することができます。「推論は、本番環境でのモデル実行による予測です」とMarolleau氏は述べています。「それを行う方法はたくさんあります。通常は、PASEを稼働できるでしょう。ILEアプリケーションがある場合は、そのモデルのREST APIと同期的に対話処理するのに使用することができます。あるいは、データベースを通じてかもしれません。あるいは、既存のプログラムからの単なるプログラム コード呼び出しかもしれません。また、IBM i でも同様に利用可能な、Kafkaや、ActiveMQや、MQTTのような、データ待ち行列のような非同期テクノロジーによる、より複雑なシナリオかもしれません。」
AIは、今後数年間で、数兆ドルもの価値を生み出すと見込まれています。IBM i プロフェッショナルは、決定性プログラミングに慣れていますが、AIが提供する機会を活用したい場合は、確率的プログラミングへ移行する必要があります。良い知らせは、IBMのスタッフやIBM i コミュニティが、このプラットフォームにAIツールを導入するべく取り組みを始めているということです。出だしは好調です。後は、IBM i ユーザー ベース次第です。新興のAIパラダイムに自分自身を慣れ親しませるのかどうか、そして大いにこのコミュニティの役に立ってきたビジネス アプリケーション ラインとAIを統合し始めるのかどうか、ということです。










