条件付きSQL I/O、第二弾
Bobからこんなメールが来ました。「やあこんにちは、Ted。年老いた犬に1つ新しい芸を教え込んでもらえると嬉しいのですが。CHAIN命令をSQLで置き換えようと思っています。あるレコードを読み取るためにファイルに対して1度CHAINを行います。そのレコードが見つからない場合は、デフォルト レコードを読み出すためにもう1度CHAINを行います。SQLで同じファイルへの2回目の読み出しを行わせるにはどのようにしたらよいのでしょうか。」
これは難しいことではありません。SQLでは同じ表に対して複数回、joinを行うのは何の問題もないからです。この記事では、データを読み出す2つの方法を説明します。1つ目の方法は簡単ですが、この方法は、表で、取得しようとしている列(フィールド)にヌル値を格納できない場合にのみ使用できます(これは、多くのIBM iのショップに当てはまります)。2つ目の方法は、列にヌル値を入れられるかどうかにかかわらず機能します。
ここでは例として、顧客マスター ファイル(CUSTMAST)と顧客住所ファイル(CUSTADDR)という2つの物理ファイルを定義します。顧客マスター ファイルには、顧客ごとに1件のレコードがあります。

顧客住所ファイルでは、顧客ごとに1つの行がある場合と、2つの行がある場合があり、それぞれの行は住所種別コード(TYPE)で識別されます。

住所種別コードで、値「1」は請求先住所、値「2」は配送先住所を表します。サンプルをできるだけ簡潔にするために、請求先住所はすべての顧客にあり、配送先住所があるのは一部の顧客のみとします。配送先住所がない場合は、請求先住所へ配送されることとします。
顧客マスターを読み出し、配送先住所をリストします。サンプルをさらに簡潔にするために、都市名、州名、および郵便番号コードは省きます(それらは、2つの住所行の列が処理されるのと同じ方法で処理されます)。 以下は、顧客の住所のデータです。
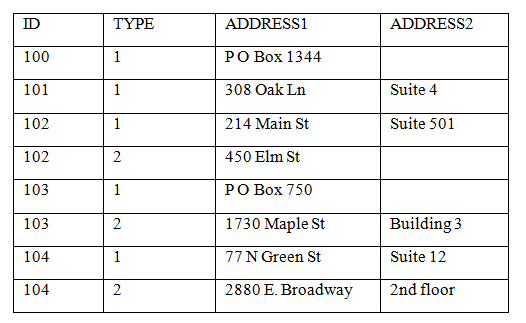
以下は、多くのショップで典型的に用いられているRPGコードです。

CUSTADDRに対する2つのCHAIN命令に注目してください。1つ目のCHAINで配送先住所が見つからない場合、プログラムは請求先住所を読み出すためにもう一度CHAINを行います。では、同じようなことは、SQLを使ってどのように行うのでしょうか。
方法1
1つ目の方法は、列にヌル値を入れることができない場合にのみ機能します。以下は、クエリーです。

顧客住所表は2回、joinが行われている点に注目してください。1回目のjoinは、配送先住所(type 2)を読み出します。2回目のjoinは、請求先住所(type 1)を読み出します。配送先住所がない場合、type 2の行からの列はヌルになります。
また、COALESCE関数にも注目してください。COALESCEは、ヌルでない最初の値をリストから選択します。Address1およびAddress2の列にはヌル値を格納できないため、表に配送先住所がない場合、クエリーは請求先住所を選択します。
前述のように、住所フィールドでヌル値が許容される場合、このクエリーはうまく機能しません。住所行の列でnullが許容されていて、使用された場合、クエリーは以下を返します。

「Dostoyevsky」に注目してください。彼の1つ目の住所の行は配送先レコードからのものですが、2つ目の住所の行は請求先レコードからのものです。配送先住所があるかどうかを判定する方法が必要です。その判定は、非常に簡単に行うことができます。
方法2
以下は、同じ顧客マスターおよび顧客住所表を、モダンなやり方で定義したものです。

キー列にはヌル値を入れることができませんが、他の列には入れることができます。以下は、同じ顧客住所のデータですが、今度はnullが入っています。
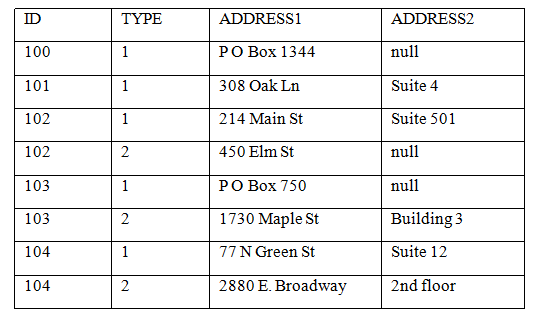
以下は、クエリーです。

COALESCE関数の代わりに、CASE式を使用しますが、CASE式が何をテストするかという点に注目してください。これを機能させるためには、
存在する場合と存在しない場合がある行からの主キーの列の1つをテストする必要があります。
ここでは、配送先住所(s.ID)からのID列をテストすることにしました。このテストでは、主キーの列がヌルであり得る唯一のケースは、joinで一致が見つからない時であるので、配送先住所があるかどうかがわかります。
以下は、このクエリーの結果です。

今度は、Dostoyevskyの住所が正しくなっています。 このシナリオは、 数年前に私が書いた記事に似ていますが、その記事では、2つ目のjoinは別のファイルに対してであり、ヌル値は考慮していませんでした。










