改めて見る SQL 記述子
注: この記事に記載のコードはここからダウンロードできます。
前号初めて見る SQL 記述子では、動的 SQL ステートメントの構築と処理における SQL 記述子の使用方法をお話ししました。今号では、動的 SQL ステートメント経由で戻された情報を処理する際に、 SQL 記述子をどのように使用できるかを調べます。
例として、SQL select ステートメントの select 節を動的に構築するプログラムを作成します。INTO 節を正しくコーディングできないので、従来、これが原因で RPG プログラムで問題が発生します。どの列を選択しているのかわからないため、SQL 記述子が救いの手を差し伸べます。
実際、構築しようとしている SQL ステートメントは、単なる動的 select 節よりもはるかに複雑ですが、わかりやすく説明するために、select 節のみ中心にお話しします。通常、select ステートメントはさまざまな表、またはビューから選択しており、表またはビューごとに異なる列名があるといったシナリオ-本当の動的ステートメントになります。
我々のサンプル・プログラムは、従業員の表からデータを選択します。最終的に、動的 SQL ステートメントのフォーマットは以下のようになります。
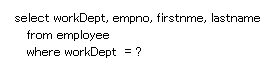
select 節では、empNo、firstName、midInit、lastName、workDept、phoneNo、hireDate、job、edLevel、sex、birthDate、salary、bonus、および comm という 14 個の列の順列と組み合わせが可能です。
サンプル・プログラムでは、取得する列を識別するため部門コードと値のリストが要求されます。このリストは、列ごとに 1 文字の識別子です。プログラムは動的 SQL ステートメントを構築し、実行して、結果セットの行ごとに要求された列を取得します。
D仕様
以下のコード片は、プログラムで使用されているグローバル変数を示します。詳細については、コードのコールアウトを参照してください。

- プログラムで使用される3つのサブプロシージャーのプロトタイプ。
- 選択された部門コードおよび列選択リストの作業フィールド。
- プログラムで使用する予定のSQL記述子の名前。
- selectステートメントから取得できるすべての列のテンプレート。この例では、これは単に従業員表のあらゆる列を示します。これらのフィールドの定義が表の列の定義と一致することが非常に重要です (詳細は後半で説明)。
- select 節の構築で使用する列名のリスト。
- 列名の配列。配列はD仕様で定義された名前のリストをオーバーレイします。したがって、EMPNOはエレメント1の値、FIRSTNME はエレメント2の値などとなります。
- 列を識別するために入力できるコードのリスト。1はEMNO、2はFIRSTNME、aはSEX、bはBIRTHDATEなどとなります。
- 列識別コードの配列。配列はF仕様で定義されたコードのリストをオーバーレイします。したがって、1はエレメント1の値、2はエレメント2の値などとなります。
主部
次のコード片は、サンプル・プログラムの主部を示します (繰り返しますが、下記のコールアウトを参照してください)。

- まず、情報の取得の際に使用する記述子の割り振りから始めます。記述子が処理する項目の最大数は14で、表の列の数になります。
- 行の選択の際に使用する部門コードを要求します。
- 'x' の値を列選択に入力するまで、ループを続けます。
- 列選択を要求し、不用意に大文字で入力されていた可能性がある必須コードが小文字に変換されていることを確認します。列選択は単に必須列のリストです (図1の (G) のコードリストによる)。
- プロシージャーを呼び出して、入力されたリストを処理します。
- これで記述子については終了し、割り振り解除できます。
setColumns() プロシージャー
次のコード片で示す setColumns() プロシージャーは、(パラメーターとして渡された) 列選択リストを SELECT 節で使用する列名 (戻り値) のリストに変換します。
列名のリストは、選択されたコードをループして作成され、forCol 配列で見つかったコードごとに、colNames 配列から対応するエレメントを追加します。最初の列名を除き、すべての列名の前にカンマが追加されます。

doVoodoo() プロシージャー
次に示す doVoodoo() プロシージャーは、必須 select ステートメントを構築、準備、実行、および処理します (コールアウトを参照)。

- プロシージャーには、WHERE 節で使用する SQL 記述子の名前、列選択リスト、部門コードが渡されます。
- getVars データ構造の内容が取得した行ごとに登録されます。
- SQL SELECT ステートメントが構築され、準備されます。setColumns() が呼び出され、列選択リストから select 節の内容を構築します。
- SQL DESCRIBE ステートメントを使用して、記述子に準備した SELECT ステートメントの情報を登録します。
- SQL GET DESCRIPTOR ステートメントを使用して、FETCH ごとに列がいくつ返されるか判断します。COUNT 変数は、記述子の項目数を識別します。
- カーソルの宣言、カーソルのオープン、結果セットの行の取り出しループ、カーソルのクローズなど標準プロセスの準備ができました。しかし、取り出しには違いがあります。
- 行を取り出す場合、記述子に取り出す必要があります。思い出してほしいのですが、select 節がどのように構築されるのかわからないので、ホスト変数またはホスト構造には直接取り出すことはできません。
- 取り出された行ごとに getRowData() プロシージャーを呼び出します。getRowData() は取り出された列を判断し、それらを getVars データ構造の対応する列に割り当てます。
- 取り出されたばかりの行のデータに対して、必要なことをすべて行います。この例では、プログラムは 3 つの列の値を表示しています。それらの列が取得されたかどうかは問いません。
getRowData() プロシージャー
次のコード片に示す getRowData() プロシージャーは、どの列が取り出されたか判断し、それらを getVars データ構造の対応する列に割り当てます。このデータ構造は呼び出し元に戻されます (コールアウトを参照)。

- プロシージャーには、処理する列の数として SQL 記述子の名前が渡されます。getVars データ構造が返されます。
- getVars はプロシージャー内で定義され、初期化されています。取り出しによりすべての列にデータが登録される保証はないため、データ構造の内容が呼び出しごとに初期化されていることが非常に重要です。
- プロシージャーは、返された列それぞれを処理します。
- SQL GET DESCRIPTOR ステートメントを使用して処理中の列の名前を取得します。「Value i」は処理する記述子の項目を示し、DB2_SYSTEM_COLUMN_NAME は、変数 colIs に配置されるシステム列名 (長い SQL 名と異なり短い 10 文字の名前) であることを示します。
- 変数 colIs の値に基づいて、SQL GET DESCRIPTOR ステートメントを使用して、列の値を getVars データ構造の該当の列に抽出します。DATA は、抽出された必要な列データであることを示します。値は直接 SQL ステートメントから割り当てられるので、getVars データ構造のフィールドの定義が表の列の定義と一致することが重要な理由がお分かり頂けたと思います。裏を返せば、これは、データは被呼プログラムのパラメーターとして返されるということです。そのため、タイプが一致するようにしなければなりません。
列の詳細情報
列情報を取得する場合、より包括的になることができます。この例では、単に列名を使用して処理しているデータの型と長さを判断しているだけです。しかし、以下のコード片で示すように、データ型の取得には SQL GET DESCRIPTOR ステートメントを使用できます。

記述子から取得できる完全な情報リスト (大規模なリストです) については、SQL リファレンス・マニュアルの GET DESCRIPTOR の記述を参照してください。
これは序の口です
表またはビューごとに列名が異なり、where 条件が異なるさまざまな表またはビューから選択するなど、通常、構造、構築方法の判断、select ステートメントはここで示したものよりはるかに複雑であることを覚えておいてください。
今号と前号が、たとえコーディングが面倒くさいと思っても、SQL 記述子がプログラムでどのように大きな柔軟性を実現できるか理解する一助となってほしいと思います。










